#Python Pandas – Find difference between two data frames
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
There were a total of 171.5 billion posts on Tumblr in 2019.
Text
Python Pandas – Find difference between two data frames
By using drop_duplicates
pd.concat([df1,df2]).drop_duplicates(keep=False)
Update :
The above method only works for those data frames that dont already have duplicates themselves. For example:
df1=pd.DataFrame({A:[1,2,3,3],B:[2,3,4,4]}) df2=pd.DataFrame({A:[1],B:[2]})
It will output like below , which is wrong
0 notes
Text
Week 1 Assignment – Running an Analysis of variance (ANOVA)
Objective:
The assignment of the week deals with Analysis of variance. Given a dataset some form of Statistical Analysis test to be performed to check and evaluate its Statistical significance.
Before getting into the crux of the problem let us understand some of the important concepts
Hypothesis testing - It is one of the most important Inferential Statistics where the hypothesis is performed on the sample data from a larger population. Hypothesis testing is a statistical assumption taken by an analyst on the nature of the data and its reason for analysis. In other words, Statistical Hypothesis testing assesses evidence provided by data in favour of or against each hypothesis about the problem.
There are two types of Hypothesis
Null Hypothesis – The null hypothesis is assumed to be true until evidence indicate otherwise. The general assumptions made on the data (people with depression are more likely to smoke)
Alternate Hypothesis – Once stronger evidences are made, one can reject Null hypothesis and accept Alternate hypothesis (One needs to come with strong evidence to challenge the null hypothesis and draw proper conclusions).In this case one needs to show evidences such that there is no relation between people smoking and their depression levels
Example:
The Null hypothesis is that the number of cigarettes smoked by the person is dependent on the person’s depression level. Based on the p-value we make conclusions either to accept the null hypothesis or fail to accept the null hypothesis(accept alternative hypothesis)
Steps involved in Hypothesis testing:
1. Choose the Null hypothesis (H0 ) and alternate hypothesis (Ha)
2. Choose the sample
3. Assess the evidence
4. Draw the conclusions
The Null hypothesis is accepted/rejected based on the p-value significance level of test
If p<= 0.05, then reject the null hypothesis (accept the alternate hypothesis)
If p > 0.05 null hypothesis is accepted
Wrongly rejecting the null hypothesis leads to type one error
Sampling variability:
The measures of the sample (subset of population) varying from the measures of the population is called Sampling variability. In other words sample results changing from sample to sample.
Central Limit theorem:
As long as adequately large samples and an adequately large number of samples are used from a population,the distribution of the statistics of the sample will be normally distributed. In other words, the more the sample the accurate it is to the population parameters.
Choosing Statistical test:
Please find the below tabulation to identify what test can be done at a given condition. Some of the statistical tools used for this are
Chi-square test of independence, ANOVA- Analysis of variance, correlation coefficient.
Explanatory variables are input or independent variable And response variable is the output variable or dependent variable.
Explanatory Response Type of test
Categorical Categorical Chi-square test
Quantitative Quantitative Pearson correlation
Categorical Quantitative ANOVA
Quantitative Categorical Chi-square test
ANOVA:
Anova F test, helps to identify, Are the difference among the sample means due to true difference among the population or merely due to sampling variability.
F = variation among sample means / by variations within groups
Let’s implement our learning in python.
The Null hypothesis here is smoking and depression levels are unrelated
The Alternate hypothesis is smoking and depression levels are related.
# importing required libraries
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
data = pd.read_csv("my_data...nesarc.csv",low_memory=False)
#setting variables you will be working with to numeric
data['S3AQ3B1'] = data['S3AQ3B1'].convert_objects(convert_numeric=True)
#data['S3AQ3B1'] = pd.to_numeric(data.S3AQ3B1)
data['S3AQ3C1'] = data['S3AQ3C1'].convert_objects(convert_numeric=True)
#data['S3AQ3C1'] = pd.to_numeric(data.S3AQ3C1)
data['CHECK321'] = data['CHECK321'].convert_objects(convert_numeric=True)
#data['CHECK321'] = pd.to_numeric(data.CHECK321)
#subset data to young adults age 18 to 25 who have smoked in the past 12 months
sub1=data[(data['AGE']>=18) & (data['AGE']<=25) & (data['CHECK321']==1)]
#SETTING MISSING DATA
sub1['S3AQ3B1']=sub1['S3AQ3B1'].replace(9, np.nan)
sub1['S3AQ3C1']=sub1['S3AQ3C1'].replace(99, np.nan)
#recoding number of days smoked in the past month
recode1 = {1: 30, 2: 22, 3: 14, 4: 5, 5: 2.5, 6: 1}
sub1['USFREQMO']= sub1['S3AQ3B1'].map(recode1)
#converting new variable USFREQMMO to numeric
sub1['USFREQMO']= sub1['USFREQMO'].convert_objects(convert_numeric=True)
# Creating a secondary variable multiplying the days smoked/month and the number of cig/per day
sub1['NUMCIGMO_EST']=sub1['USFREQMO'] * sub1['S3AQ3C1']
sub1['NUMCIGMO_EST']= sub1['NUMCIGMO_EST'].convert_objects(convert_numeric=True)
ct1 = sub1.groupby('NUMCIGMO_EST').size()
print (ct1)
print(sub1['MAJORDEPLIFE'])
# using ols function for calculating the F-statistic and associated p value
The ols is the ordinary least square function takes the response variable NUMCIGMO_EST and its explanatory variable MAJORDEPLIFE, C is indicated to specify that it’s a categorical variable.
model1 = smf.ols(formula='NUMCIGMO_EST ~ C(MAJORDEPLIFE)', data=sub1)
results1 = model1.fit()
print (results1.summary())
Inference – Since the p value is greater than 0.05, we accept the null hypothesis that the sample means are statistically equal. And there is no association between depression levels and cigarette smoked.
sub2 = sub1[['NUMCIGMO_EST', 'MAJORDEPLIFE']].dropna()
print ('means for numcigmo_est by major depression status')
m1= sub2.groupby('MAJORDEPLIFE').mean()
print (m1)
print ('standard deviations for numcigmo_est by major depression status')
sd1 = sub2.groupby('MAJORDEPLIFE').std()
print (sd1)
Since the null hypothesis is true we conclude that the sample mean and standard deviation of the two samples are statistically equal. From the sample statistics we infer that the depression levels and smoking are unrelated to each other
Till now, we ran the ANOVA test for two levels of the categorical variable(MAJORDEPLIFE, 0,1) Lets now look at the categorical variable(ETHRACE2A,White, Black, American Indian, Asian native and Latino) having five levels and see how the differences in the mean are captured.
The problem here is, The F-statistic and ‘p’ value does not provide any insight as to why the null hypothesis is rejected when there are multiple levels in categorical Explanatory variable.
The significant ANOVA does not tell which groups are different from the others. To determine this we would need to perform post-hoc test for ANOVA
Why Post-hoc tests for ANOVA?
Post hoc test known as after analysis test, This is performed to prevent excessive Type one error. Not implementing this leads to family wise error rate, given by the formula
FWE = 1 – (1 – αIT)C
Where:
αIT = alpha level for an individual test (e.g. .05),
c = Number of comparisons.
Post-hoc tests are designed to evaluate the difference between the pair of means while protecting against inflation of type one error.
Let’s continue the code to perform post-hoc test.
# Importing the library
Import statsmodels.stats.multicomp as multi
# adding the variable of interest to a separate data frame
sub3 = sub1[['NUMCIGMO_EST', 'ETHRACE2A']].dropna()
# calling the ols function and passing the explanatory categorical and response variable
model2 = smf.ols(formula='NUMCIGMO_EST ~ C(ETHRACE2A)', data=sub3).fit()
print(model2.summary())
print ('means for numcigmo_est by major depression status')
m2= sub3.groupby('ETHRACE2A').mean()
print(m2)
print('standard deviations for numcigmo_est by major depression status')
sd2 = sub3.groupby('ETHRACE2A').std()
print(sd2)
# Include required parameters in the MultiComparison function and then run the post-hoc TukeyHSD test
mc1 = multi.MultiComparison(sub3['NUMCIGMO_EST'], sub3['ETHRACE2A'])
res1 = mc1.tukeyhsd()
print(res1.summary())
1 note
·
View note
Text
Python in Shaping the Future of Machine Learning 5
How Amazon Is Dazzling The World With Ai & Ml
You can use either of them, as both give just about the same outcomes specifically in case of CART analytics as shown in below determination. Entropy in simpler terms is the measure of randomness or uncertainty.
In the above example, a choice tree is being used for a classification drawback to resolve whether an individual is fit or unit. The depth of the tree is referred to the length of the tree from root node to leaf. If you could have disposable revenue to spend then I’d highly recommend hiring a mentor who can stroll you through your issues. Income share mentorships make new opportunities accessible to people who can’t afford the professional time or discover professional knowledge scientists to be taught from.
” There are many assets across the net, but I don’t wish to give anyone the mistaken impression that the path to data science is as simple as taking a few MOOCs. Unless you have already got a robust quantitative background, the highway to becoming a knowledge scientist might be challenging but not inconceivable. A knowledge scientist will never thrive if he/she doesn’t understand what to take a look at to run when and the way to interpret their findings.
Stock Market Clustering Project — In this project, you'll use a K-means clustering algorithm to establish related corporations by discovering correlations amongst inventory market actions over a given time span. We have tried to take an extra thrilling approach to Machine Learning, by not working on simply the idea of it, however as a substitute by using the technology to actually build actual-world initiatives that you should use. Furthermore, you will learn how to write the codes after which see them in motion and actually learn to assume like a machine studying skilled. In this weblog, we'll take a look at initiatives divided largely into two totally different levels i.e. First, projects talked about under the beginner heading cover important ideas of a specific technique/algorithm.

But that is the proper guide for superior-intermediate to professional data scientists. If you need to know how to work professionally as a knowledge scientist, this guide is for you. But this is only for intermediate, advanced, and skilled knowledge scientists since you have to know the fundamentals before starting on this guide. P is the likelihood of a knowledge level belonging to class 1 as predicted by the model.
And check out the top 5 rows utilizing the head() Pandas DataFrame perform. This is how the K Nearest Neighbours algorithm works in principle. As you possibly can see, visualizing the data is a big assist to get an intuitive picture of what the k values must be. Finally, we return a category as output which is closest to the new knowledge level, in accordance with various measures. The measures used include Euclidean distance amongst others.
Now that we now have defined our phrases, let’s move to the lessons of Machine Learning or ML algorithms. The why must be predicted using the ML mannequin trained on the seen knowledge. The predicted variable is often known as the dependent variable. For example, information of a thousand customers with their age, gender, time of entry and exit and their purchases. The subsequent question I all the time get is, “What can I do to develop these abilities?
youtube
Experienced working with skilled builders could make or break your capability to land a knowledge science position. Learning knowledge science will never be straightforward without any assistance from the community or from somebody who's prepared to help novices. These someones are the ones which might be making up our wonderful LinkedIn Data Science Community.
Similarly, tasks beneath superior class contain the application of multiple algorithms along with key ideas to achieve the answer of the problem at hand. Thus, we have designed a comprehensive listing of projects in the Machine Learning course that offers a palms-on experience with ML and how to construct precise initiatives using the Machine Learning algorithms. Furthermore, this course is an observation up to our Introduction to Machine Learning course and delves further deeper into the sensible applications of Machine Learning. Changes aren't just challenges, they are additionally alternatives for much higher-paying and much much less laborious jobs than the roles you hold at present. And, if by probability, you happen to be a scholar studying this article, you now know which business you should concentrate on – fully. All the best, and bear in mind to benefit from the process of studying.
Regardless of your age, that is the best time to be alive – ever. Because area knowledge is out there extra widely today than at any time up to now. And make the right selections at the right instances – and no, it's never too late when you're high quality trainers able to mentor you. May the fun of studying a completely new idea with really enlightened insight never leave you. Dimensionless.in is an elite information science training firm that imparts trade degree expertise and knowledge to those with an actual thirst to study. Training is given from the fundamentals, resulting in a strong basis.

If you need to be an information scientist, not having a decent Kaggle profile is inexcusable. Kaggle will be like a showcase of your information science expertise to the whole world. Even when you don’t rank very excessive, consistency and practice can get you there most of the time. This single book incorporates a number of the latest and the most effective methods to attain what you should be a professional information scientist. Every chapter has multiple case research taken from the experiences within the industry.Vincent Granville is recognized worldwide as probably the greatest-recognized useful resource in information science. The level is slightly advanced, and it is not beneficial for novices.
The greatest potential break up will be the one with the lowest general entropy. This is because of decreased entropy, lower uncertainty and hence more probability. Dropping the variables that are of least importance in deciding. In Titanic dataset columns such as name, cabin no. ticket no. is of least importance. Decision Trees can be utilized for classification as well as regression problems. That’s why they are called Classification or Regression Trees.
Therefore, our prediction could be that the unseen flower is a Rose. Notice that our prior probabilities of both the lessons favoured Sunflower. But as soon as we factored the data about thorns, our decision changed. For all N factors, we sum the squares of the distinction of the predicted value of Y by the model, i.e. Y’ and the precise worth of the anticipated variable for that point, i.e.
They want a stable understanding of algebra and calculus. In good old days, Math was a subject based mostly on common sense and the necessity to resolve primary issues based on logic. This hasn’t modified a lot, though the size has blown up exponentially. A statistical sensibility provides a stable foundation for several evaluation tools and methods, that are utilized by a knowledge scientist to build their fashions and analytic routines. An information scientist is not going to conclude, decide, or resolve without enough data.
This is the essence of the ML algorithm that platforms such as Amazon and Flipkart use for each customer. Their algorithms are much more complex, but that is their essence. Determine sort of characteristic capabilities decide whether a kind of feature is categorical or continuous. There are 2 criterias for the function to be known as categorical, first if the feature is of knowledge sort string and second, the no. of categories for the function is less than 10. I actually have used Information Gain Entropy as a measure of impurity.
With the right strategy and by trying at the right corners, you'll find information scientist mentors who might help you bridge the hole between theoretical and sensible functions of data science. Development of algorithms for Computer Aided Detection of early-stage breast most cancers among others. KKD cup is a well-liked knowledge mining and knowledge discovery competition held annually. It is likely one of the first-ever data science competitors which dates again to 1997. With the growing demand to research giant amounts of data inside small time frames, organizations choose working with the data immediately over samples. Consequently, this presents a herculean task for an information scientist with a limitation of time. Sports Betting… Predict field scores given the info available at the time proper before each new recreation.
Regression analysis is a type of predictive modeling method which investigates the relationship between dependent and independent variables. Regression goals at finding a straight line which may accurately depict the precise relationship between the 2 variables. Data is rising day by day, and it is unimaginable to understand all of the knowledge with higher velocity and higher accuracy. More than 80% of the information is unstructured that's audios, movies, photographs, paperwork, graphs, and so on. Finding patterns in knowledge on planet earth is impossible for human brains. The knowledge has been very large and the time taken to compute would improve solely. This is the place Machine Learning comes into motion, to help people with significant information in minimum time.
It may be proven that there isn't an absolute “best” criterion which would be independent of the final goal of the clustering. Consequently, it is the consumer which should supply this criterion, in such a means that the results of the clustering will go well with their needs. Clustering is likely one of the most important unsupervised learning problems; so, like each other's downside of this kind, it deals with finding a structure in a collection of unlabeled information.
In this article, we shall be looking at why there's even a necessity for people to have mentors in knowledge science and the way we can discover them. Although Data Science has been around us ever since the 1960s, it has only gained traction in the previous couple of a long time. This is one of the major reasons why budding knowledge scientists find it quite challenging to find the best mentors.
Now, anybody with discipline and persistence can study information science and turn out to be a data scientist. The coaching obtained is customized to cater to the needs of each pupil. These days, just having an impressive profile on Kaggle might be enough to land you a job interview at the very least. Kaggle is a site that has been hosting information science competitions for a few years. The competition is immense and intense, however so are the tutorials and the articles are additionally equally highly effective and instructive.
Explore more on Data Science Course In Hyderabad
360DigiTMG - Data Analytics, Data Science Course Training Hyderabad
Address:-2-56/2/19, 3rd floor,, Vijaya towers, near Meridian school,, Ayyappa Society Rd, Madhapur,, Hyderabad, Telangana 500081
Contact us ( 099899 94319 )
0 notes
Text
Why Python is used in data science? How data science courses help in a successful career post COVID pandemic?

Data science has tremendous growth opportunities and is one of the hot careers in the current world. Many businesses are thriving for skilled data scientists. Data science requires many skills to become an expert – One of the important skills is Python programming. Python is a programming language widely used in many fields. It is considered as the king of the coding world. Data scientists extensively use this language and even beginners find it easy to learn the Python language. To learn this language, there are many Python data science courses that guide and train you in an effective way.
What is Python?
Python is an interpreted and object-oriented programming language. It is an easily understandable language whose syntaxes can be grasped by a beginner quickly. It was found by Guido in 1991. It is supported in operating systems like Linux, Windows, macOS, and a lot more. The Python is developed and managed by the Python software foundation.
The second version of Python was released in 2000. It features list comprehension and reference counting. This version was officially stopped functioning in 2020. Currently, only the Python version 3.5x and later versions are supported.
Why Python is used in data science?
Python is the most preferred programming language by the data scientists as it effectively resolves tasks. It is one of the top data science tools used in various industries. It is an ideal language to implement algorithms. Python’s scikit-learn is a vital tool that the data scientist find it useful while solving many machine learning tasks. Data science uses Python libraries to solve a task.
Python is very good when it comes to scalability. It gives you flexibility and multiple solutions for different problems. It is faster than Matlab. The main reason why YouTube started working in Python is because of its exceptional scalability.
Features of Python language
Python has a syntax that can be understood easily.
It has a vast library and community support.
We can easily test codes as it has interactive modes.
The errors that arise can be easily understood and cleared quickly.
It is free software, and it can be downloaded online. Even there are free online Python compilers available.
The code can be extended by adding modules. These modules can also be implemented in other languages like C, C++, etc.
It offers a programmable interface as it is expressive in nature.
We can code Python anywhere.
The access to this language is simple. So we can easily make the program working.
The different types of Python libraries used for data science
1.Matplotlib
Matplotlib is used for effective data visualization. It is used to develop line graphs, pie charts, histograms efficiently. It has interactive features like zooming and planning the data in graphics format. The analysis and visualization of data are vital for a company. This library helps to complete the work efficiently.
2.NumPy
NumPy is a library that stands for Numerical Python. As the name suggests, it does statistical and mathematical functions that effectively handles a large n-array. This helps in improving the data and execution rate.
3.Scikit-learn
Scikit- learn is a data science tool used for machine learning. It provides many algorithms and functions that help the user through a constant interface. Therefore, it offers active data sets and capable of solving real-time problems more efficiently.
4.Pandas
Pandas is a library that is used for data analysis and manipulation. Even though the data to be manipulated is large, it does the manipulation job easily and quickly. It is an absolute best tool for data wrangling. It has two types of data structures .i.e. series, and data frame. Series takes care of one-dimensional data, and the data frame takes care of two-dimensional data.
5.Scipy
Scipy is a popular library majorly used in the data science field. It basically does scientific computation. It contains many sub-modules used primarily in science and engineering fields for FFT, signal, image processing, optimization, integration, interpolation, linear algebra, ODE solvers, etc.
Importance of data science
Data scientists are becoming more important for a company in the 21st century. They are becoming a significant factor in public agencies, private companies, trades, products and non-profit organizations. A data scientist plays as a curator, software programmer, computer scientist, etc. They are the central part of managing the collection of digital data. According to our analysis, we have listed below the major reasons why data science is important in developing the world’s economy.
Data science helps to create a relationship between the company and the client. This connection helps to know the customer’s requirements and work accordingly.
Data scientists are the base for the functioning and the growth of any product. Thus they become an important part as they are involved in doing significant tasks .i.e. data analysis and problem-solving.
There is a vast amount of data travelling around the world and if it is used efficiently, it results in the successful growth of the product.
The resulting products have a storytelling capability that creates a reliable connection among the customers. This is one of the reasons why data science is popular.
It can be applied to various industries like health-care, travel, software companies, etc.
Big data analytics is majorly used to solve the complexities and find a solution for the problems in IT companies, resource management, and human resource.
It greatly influences the retail or local sellers. Currently, due to the emergence of many supermarkets and shops, the customers approaching the retail sellers are drastically decreased. Thus data analytics helps to build a connection between the customers and local sellers.
Are you finding it difficult to answer the questions in an interview? Here are some frequently asked data science interview questions on basic concepts
Q. How to maintain a deployed model?
To maintain a deployed model, we have to
Monitor
Evaluate
Compare
Rebuild
Q. What is random forest model?
Random forest model consists of several decision trees. If you split the data into different sections and assign each group of data a decision tree, the random forest models combine all the trees.
Q. What are recommendation systems?
A recommendation system recommends the products to the users based on their previous purchases or preferences. There are mainly two areas .i.e. collaborative filtering and content-based filtering.
Q. Explain the significance of p-value?
P-value <= 0.5 : rejects the null-hypothesis
P-value > 0.5 : accepts null-hypothesis
P-value = 0.5 : it will either except or deny the null-hypothesis
Q. What is logistic regression?
Logistic regression is a method to obtain a binary result from a linear combination of predictor variables.
Q. What are the steps in building a decision tree?
Take the full data as the input.
Split the dataset in such a way that the separation of the class is maximum.
Split the input.
Follow steps 1 and 2 to the separated data again.
Stop this process after the complete data is separated.
Best Python data science courses
Many websites provide Data Science online courses. Here are the best sites that offer data science training based on Python.
GreatLearning
Coursera
EdX
Alison
Udacity
Skillathon
Konvinity
Simplilearn
How data science courses help in a successful career post-COVID-19 pandemic?
The economic downfall due to COVID-19 impacts has lead to upskill oneself as the world scenarios are changing drastically. Adding skills to your resume gives an added advantage of getting a job easily. The businesses are going to invest mainly in two domains .i.e. data analysis of customer’s demand and understanding the business numbers. It is nearly impossible to master in data science, but this lockdown may help you become a professional by indulging in data science programs.
Firstly, start searching for the best data science course on the internet. Secondly, make a master plan in such a way that you complete all the courses successfully. Many short-term courses are there online that are similar to the regular courses, but you can complete it within a few days. For example, Analytix Labs are providing these kinds of courses to upskill yourself. So this is the right time where you are free without any work and passing time. You can use this time efficiently by enrolling in these courses and become more skilled in data science than before. These course providers also give a data science certification for the course you did; this will help to build your resume.
Data science is a versatile field that has a broad scope in the current world. These data scientists are the ones who are the pillars of businesses. They use various factors like programming languages, machine learning, and statistics in solving a real-world problem. When it comes to programming languages, it is best to learn Python as it is easy to understand and has an interactive interface. Make efficient use of time in COVID-19 lockdown to upskill and build yourself.
0 notes
Photo

Pandas: The Swiss Army Knife for Your Data, Part 2
This is part two of a two-part tutorial about Pandas, the amazing Python data analytics toolkit.
In part one, we covered the basic data types of Pandas: the series and the data frame. We imported and exported data, selected subsets of data, worked with metadata, and sorted the data.
In this part, we'll continue our journey and deal with missing data, data manipulation, data merging, data grouping, time series, and plotting.
Dealing With Missing Values
One of the strongest points of pandas is its handling of missing values. It will not just crash and burn in the presence of missing data. When data is missing, pandas replaces it with numpy's np.nan (not a number), and it doesn't participate in any computation.
Let's reindex our data frame, adding more rows and columns, but without any new data. To make it interesting, we'll populate some values.
>>> df = pd.DataFrame(np.random.randn(5,2), index=index, columns=['a','b']) >>> new_index = df.index.append(pd.Index(['six'])) >>> new_columns = list(df.columns) + ['c'] >>> df = df.reindex(index=new_index, columns=new_columns) >>> df.loc['three'].c = 3 >>> df.loc['four'].c = 4 >>> df a b c one -0.042172 0.374922 NaN two -0.689523 1.411403 NaN three 0.332707 0.307561 3.0 four 0.426519 -0.425181 4.0 five -0.161095 -0.849932 NaN six NaN NaN NaN
Note that df.index.append() returns a new index and doesn't modify the existing index. Also, df.reindex() returns a new data frame that I assign back to the df variable.
At this point, our data frame has six rows. The last row is all NaNs, and all other rows except the third and the fourth have NaN in the "c" column. What can you do with missing data? Here are options:
Keep it (but it will not participate in computations).
Drop it (the result of the computation will not contain the missing data).
Replace it with a default value.
Keep the missing data --------------------- >>> df *= 2 >>> df a b c one -0.084345 0.749845 NaN two -1.379046 2.822806 NaN three 0.665414 0.615123 6.0 four 0.853037 -0.850362 8.0 five -0.322190 -1.699864 NaN six NaN NaN NaN Drop rows with missing data --------------------------- >>> df.dropna() a b c three 0.665414 0.615123 6.0 four 0.853037 -0.850362 8.0 Replace with default value -------------------------- >>> df.fillna(5) a b c one -0.084345 0.749845 5.0 two -1.379046 2.822806 5.0 three 0.665414 0.615123 6.0 four 0.853037 -0.850362 8.0 five -0.322190 -1.699864 5.0 six 5.000000 5.000000 5.0
If you just want to check if you have missing data in your data frame, use the isnull() method. This returns a boolean mask of your dataframe, which is True for missing values and False elsewhere.
>>> df.isnull() a b c one False False True two False False True three False False False four False False False five False False True six True True True
Manipulating Your Data
When you have a data frame, you often need to perform operations on the data. Let's start with a new data frame that has four rows and three columns of random integers between 1 and 9 (inclusive).
>>> df = pd.DataFrame(np.random.randint(1, 10, size=(4, 3)), columns=['a','b', 'c']) >>> df a b c 0 1 3 3 1 8 9 2 2 8 1 5 3 4 6 1
Now, you can start working on the data. Let's sum up all the columns and assign the result to the last row, and then sum all the rows (dimension 1) and assign to the last column:
>>> df.loc[3] = df.sum() >>> df a b c 0 1 3 3 1 8 9 2 2 8 1 5 3 21 19 11 >>> df.c = df.sum(1) >>> df a b c 0 1 3 7 1 8 9 19 2 8 1 14 3 21 19 51
You can also perform operations on the entire data frame. Here is an example of subtracting 3 from each and every cell:
>>> df -= 3 >>> df a b c 0 -2 0 4 1 5 6 16 2 5 -2 11 3 18 16 48
For total control, you can apply arbitrary functions:
>>> df.apply(lambda x: x ** 2 + 5 * x - 4) a b c 0 -10 -4 32 1 46 62 332 2 46 -10 172 3 410 332 2540
Merging Data
Another common scenario when working with data frames is combining and merging data frames (and series) together. Pandas, as usual, gives you different options. Let's create another data frame and explore the various options.
>>> df2 = df // 3 >>> df2 a b c 0 -1 0 1 1 1 2 5 2 1 -1 3 3 6 5 16
Concat
When using pd.concat, pandas simply concatenates all the rows of the provided parts in order. There is no alignment of indexes. See in the following example how duplicate index values are created:
>>> pd.concat([df, df2]) a b c 0 -2 0 4 1 5 6 16 2 5 -2 11 3 18 16 48 0 -1 0 1 1 1 2 5 2 1 -1 3 3 6 5 16
You can also concatenate columns by using the axis=1 argument:
>>> pd.concat([df[:2], df2], axis=1) a b c a b c 0 -2.0 0.0 4.0 -1 0 1 1 5.0 6.0 16.0 1 2 5 2 NaN NaN NaN 1 -1 3 3 NaN NaN NaN 6 5 16
Note that because the first data frame (I used only two rows) didn't have as many rows, the missing values were automatically populated with NaNs, which changed those column types from int to float.
It's possible to concatenate any number of data frames in one call.
Merge
The merge function behaves in a similar way to SQL join. It merges all the columns from rows that have similar keys. Note that it operates on two data frames only:
>>> df = pd.DataFrame(dict(key=['start', 'finish'],x=[4, 8])) >>> df key x 0 start 4 1 finish 8 >>> df2 = pd.DataFrame(dict(key=['start', 'finish'],y=[2, 18])) >>> df2 key y 0 start 2 1 finish 18 >>> pd.merge(df, df2, on='key') key x y 0 start 4 2 1 finish 8 18
Append
The data frame's append() method is a little shortcut. It functionally behaves like concat(), but saves some key strokes.
>>> df key x 0 start 4 1 finish 8 Appending one row using the append method() ------------------------------------------- >>> df.append(dict(key='middle', x=9), ignore_index=True) key x 0 start 4 1 finish 8 2 middle 9 Appending one row using the concat() ------------------------------------------- >>> pd.concat([df, pd.DataFrame(dict(key='middle', x=[9]))], ignore_index=True) key x 0 start 4 1 finish 8 2 middle 9
Grouping Your Data
Here is a data frame that contains the members and ages of two families: the Smiths and the Joneses. You can use the groupby() method to group data by last name and find information at the family level like the sum of ages and the mean age:
df = pd.DataFrame( dict(first='John Jim Jenny Jill Jack'.split(), last='Smith Jones Jones Smith Smith'.split(), age=[11, 13, 22, 44, 65])) >>> df.groupby('last').sum() age last Jones 35 Smith 120 >>> df.groupby('last').mean() age last Jones 17.5 Smith 40.0
Time Series
A lot of important data is time series data. Pandas has strong support for time series data starting with data ranges, going through localization and time conversion, and all the way to sophisticated frequency-based resampling.
The date_range() function can generate sequences of datetimes. Here is an example of generating a six-week period starting on 1 January 2017 using the UTC time zone.
>>> weeks = pd.date_range(start='1/1/2017', periods=6, freq='W', tz='UTC') >>> weeks DatetimeIndex(['2017-01-01', '2017-01-08', '2017-01-15', '2017-01-22', '2017-01-29', '2017-02-05'], dtype='datetime64[ns, UTC]', freq='W-SUN')
Adding a timestamp to your data frames, either as data column or as the index, is great for organizing and grouping your data by time. It also allows resampling. Here is an example of resampling every minute data as five-minute aggregations.
>>> minutes = pd.date_range(start='1/1/2017', periods=10, freq='1Min', tz='UTC') >>> ts = pd.Series(np.random.randn(len(minutes)), minutes) >>> ts 2017-01-01 00:00:00+00:00 1.866913 2017-01-01 00:01:00+00:00 2.157201 2017-01-01 00:02:00+00:00 -0.439932 2017-01-01 00:03:00+00:00 0.777944 2017-01-01 00:04:00+00:00 0.755624 2017-01-01 00:05:00+00:00 -2.150276 2017-01-01 00:06:00+00:00 3.352880 2017-01-01 00:07:00+00:00 -1.657432 2017-01-01 00:08:00+00:00 -0.144666 2017-01-01 00:09:00+00:00 -0.667059 Freq: T, dtype: float64 >>> ts.resample('5Min').mean() 2017-01-01 00:00:00+00:00 1.023550 2017-01-01 00:05:00+00:00 -0.253311
Plotting
Pandas supports plotting with matplotlib. Make sure it's installed: pip install matplotlib. To generate a plot, you can call the plot() of a series or a data frame. There are many options to control the plot, but the defaults work for simple visualization purposes. Here is how to generate a line graph and save it to a PDF file.
ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2017', periods=1000)) ts = ts.cumsum() ax = ts.plot() fig = ax.get_figure() fig.savefig('plot.pdf')
Note that on macOS, Python must be installed as a framework for plotting with Pandas.
Conclusion
Pandas is a very broad data analytics framework. It has a simple object model with the concepts of series and data frame and a wealth of built-in functionality. You can compose and mix pandas functions and your own algorithms.
Additionally, don’t hesitate to see what we have available for sale and for study in the marketplace, and don't hesitate to ask any questions and provide your valuable feedback using the feed below.
Data importing and exporting in pandas are very extensive too and ensure that you can integrate it easily into existing systems. If you're doing any data processing in Python, pandas belongs in your toolbox.
by Gigi Sayfan via Envato Tuts+ Code http://ift.tt/2gaPZ24
2 notes
·
View notes
Text
Python For Trading: An Introduction
Python For Trading: An Introduction http://bit.ly/2NxMZ1e
By: Vibhu Singh, Shagufta Tahsildar, and Rekhit Pachanekar
This article is a brief guide to Python, that covers everything you need to know about Python programming language. It covers a wide variety of topics rights from the basics leading to the use of Python for Trading. We are moving towards the world of automation and thus, there is always a demand for people with a programming language experience. When it comes to the world of algorithmic trading, it is necessary to learn a programming language in order to make your trading algorithms smarter as well as faster. It is true that you can outsource the coding part of your strategy to a competent programmer but it will be cumbersome later when you have to tweak your strategy according to the changing market scenario. Python, a programming language which was conceived in the late 1980s by Guido van Rossum, has witnessed humongous growth, especially in the recent years due to its ease of use, extensive libraries, and elegant syntax. In this article we would cover the following:
Introduction to Python
Python vs. C++ vs. R
Applications of Python in Finance
Getting started with Python
Installation Guide for Python
Popular Python Libraries / Python Packages
How to import data to Python?
Creating, backtesting and evaluating a trading strategy in Python
Python Books and References
Why is it called Python?
One of the commonly asked questions is: How did a programming language land up with a name like ‘Python’?
Well, Guido, the creator of Python, needed a short, unique, and a slightly mysterious name and thus decided on “Python” while watching a comedy series called “Monty Python’s Flying Circus”. If you are curious on knowing the history of Python as well as what is Python and its applications, you can always refer to the first chapter of the Python Handbook, which serves as your guide as you start your journey in Python. Before we understand the core concepts of Python and its application in finance as well as Python trading, let us understand the reason we should learn Python. Having knowledge of a popular programming language is the building block to becoming a professional algorithmic trader. With rapid advancements in technology every day - it is difficult for programmers to learn all the programming languages.
Which Programming Language Should I learn for Algorithmic Trading?
The answer to this question is that there is nothing like a “BEST” language for algorithmic trading. There are many important concepts taken into consideration in the entire trading process before choosing a programming language:
cost,
performance,
resiliency,
modularity, and
various other trading strategy parameters.
Each programming language has its own pros and cons and a balance between the pros and cons based on the requirements of the trading system will affect the choice of programming language an individual might prefer to learn. Every organization has a different programming language based on their business and culture.
What kind of trading system will you use?
Are you planning to design an execution based trading system?
Are you in need of a high-performance backtester?
Based on the answers to all these questions, one can decide on which programming language is the best for algorithmic trading. However, to answer the above questions let’s explore the various programming languages used for algorithmic trading with a brief understanding of the pros and cons of each.
Why Python for Trading?
Quant traders require a scripting language to build a prototype of the code. In that regard, Python has a huge significance in the overall trading process as it finds applications in prototyping quant models particularly in quant trading groups in banks and hedge funds. Preferred choice: Python trading has become a preferred choice recently as Python is open-source and all the packages are free for commercial use. Helpful: Most of the quant traders prefer Python trading as it helps them:
build their own data connectors,
execution mechanisms,
backtest,
risk and order management,
walk forward analysis, and
optimize testing modules.
Developers: Algorithmic trading developers are often confused about whether to choose an open-source technology or a commercial/proprietary technology. Feasibility: Before deciding on this it is important to consider:
the activity of the community surrounding a particular programming language,
the ease of maintenance,
ease of installation,
documentation of the language, and
the maintenance costs.
Convenience: Python trading has gained traction in the quant finance community as it makes it easy to build intricate statistical models with ease due to the availability of sufficient scientific libraries like:
Pandas,
NumPy,
PyAlgoTrade,
Pybacktest, and more.
First updates: First updates to python trading libraries are a regular occurrence in the developer community. Suggested read: What Makes Python Most Preferred Language For Algorithmic Traders
Python at present
In fact, according to the Developer Survey Results 2019 at StackOverflow, Python is the fastest-growing programming language.
It was also found that among the languages the people were most interested to learn,[1] Python was the most desired programming language.

Benefits of Using Python in Algorithmic Trading
Out of the many benefits that Python programming language offers, following are the most notable:
Parallelization and huge computational power of Python give scalability to the portfolio.
Python makes it easier to write and evaluate algo trading structures because of its functional programming approach. The code can be easily extended to dynamic algorithms for trading.
Python can be used to develop some great trading platforms whereas using C or C++ is a hassle and time-consuming job.
Python trading is an ideal choice for people who want to become pioneers with dynamic algo trading platforms.
For individuals new to algorithmic trading, the Python code is easily readable and accessible.
It is comparatively easier to fix new modules to Python language and make it expansive.
The existing modules also make it easier for algo traders to share functionality amongst different programs by decomposing them into individual modules which can be applied to various trading architectures.
When using Python for trading it requires fewer lines of code due to the availability of extensive libraries.
Quant traders can skip various steps which other languages like C or C++ might require.
This also brings down the overall cost of maintaining the trading system.
With a wide range of scientific libraries in Python, algorithmic traders can perform any kind of data analysis at an execution speed that is comparable to compiled languages like C++.
Drawbacks of Using Python in Algorithmic Trading
Just like every coin has two faces, there are some drawbacks of Python trading. In Python, every variable is considered as an object, so every variable will store unnecessary information like size, value and reference pointer. When storing millions of variables if memory management is not done effectively, it could lead to memory leaks and performance bottlenecks. However, for someone who is starting out in the field of programming, the pros of Python trading exceed the drawbacks making it a supreme choice of programming language for algorithmic trading platforms.
Algorithmic Trading - Python vs. C++
A compiled language like C++ is often an ideal programming language choice if the backtesting parameter dimensions are large. However, Python makes use of high-performance libraries like Pandas or NumPy for backtesting to maintain competitiveness with its compiled equivalents. Between the two, Python or C++, the language to be used for backtesting and research environments will be decided on the basis of the requirements of the algorithm and the available libraries. Choosing C++ or Python will depend on the trading frequency. Python language is ideal for 5-minute bars but when moving downtime sub-second time frames this might not be an ideal choice. If speed is a distinctive factor to compete with your competition then using C++ is a better choice than using Python for Trading. C++ is a complicated language, unlike Python which even beginners can easily read, write and learn. The following is the latest study by Stackoverflow that shows Python as among the Top 3 Popular programming languages.[2]

Why use Python instead of R?
We have seen above that Python is preferred to C++ in most of the situations. But what about other programming languages, like R? Well, the answer is that you can use either based on your requirements but as a beginner Python is preferred as it is easier to grasp and has a cleaner syntax. Python already consists of a myriad of libraries, which consists of numerous modules which can be used directly in our program without the need of writing code for the function. Trading systems evolve with time and any programming language choices will evolve along with them. If you want to enjoy the best of both worlds in algorithmic trading i.e. benefits of a general-purpose programming language and powerful tools of the scientific stack - Python would most definitely satisfy all the criteria.
Applications of Python in Finance
Apart from its huge applications in the field of web and software development, today, Python finds applications in many fields.
Python and Machine Learning
One of the reasons why Python is being extensively used nowadays is due to its applications in the field of Machine Learning (ML). Machines are trained to learn from the historical data and act accordingly on some new data. Hence, it finds its use across various domains such as:
Medicine (to learn and predict diseases),
Marketing (to understand and predict user behaviour) and
Now even in Trading (to analyze and build strategies based on financial data).
Python and Finance
Today, finance professionals are enrolling for Python trading courses to stay relevant in today’s world of finance. Gone are the days when computer programmers and Finance professionals were in separate divisions. Companies are hiring computer engineers and train them in the world of finance as the world of algorithmic trading becomes the dominant way of trading in the world.
Python and the Markets
Already 70% of the US stock exchange order volume has been done with algorithmic trading. Thus, it makes sense for Equity traders and the like to acquaint themselves with any programming language to better their own trading strategy. But before we move into it, let’s understand the components which we will be installing and using before getting started with Python.
Getting started with Python
After going through the advantages of using Python, let’s understand how you can actually start using it. Let's talk about the various components of Python.
Components of Python
Anaconda – Anaconda is a distribution of Python, which means that it consists of all the tools and libraries required for the execution of our Python code. Downloading and installing libraries and tools individually can be a tedious task, which is why we install Anaconda as it consists of a majority of the Python packages which can be directly loaded to the IDE to use them.
Spyder IDE - IDE or Integrated Development Environment, is a software platform where we can write and execute our codes. It basically consists of a code editor, to write codes, a compiler or interpreter to convert our code into machine-readable language and a debugger to identify any bugs or errors in your code. Spyder IDE can be used to create multiple projects of Python.
Jupyter Notebook – Jupyter is an open-source application that allows us to create, write and implement codes in a more interactive format. It can be used to test small chunks of code, whereas we can use the Spyder IDE to implement bigger projects.
Conda – Conda is a package management system which can be used to install, run and update libraries.
Note: Spyder IDE and Jupyter Notebook are a part of the Anaconda distribution; hence they need not be installed separately.
Setup Python
Now that we're clear about the components of Python, let's understand how we will setup Python. The first step is definitely to have Python on your system to start using it. For that, we have provided a step by step guide on how to install and run Python on your system.
Installation Guide for Python
Let us now begin with the installation process of Anaconda. Follow the steps below to install and set up Anaconda on your Windows system:
Step 1
Visit the Anaconda website to download Anaconda. Click on the version you want to download according to your system specifications (64-bit or 32-bit).

Step 2
Run the downloaded file and click “Next” and accept the agreement by clicking “I agree”.


Step 3
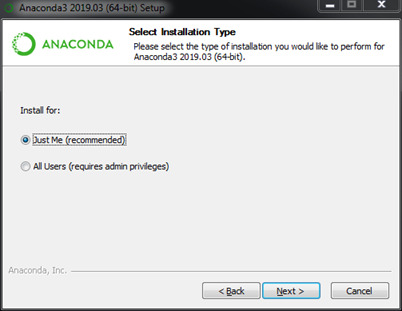
In select installation type, choose “Just Me (Recommended)” and choose the location where you wish to save Anaconda and click on Next.

Step 4 In Advanced Options, checkmark both the boxes and click on Install. Once it is installed, click “Finish”.

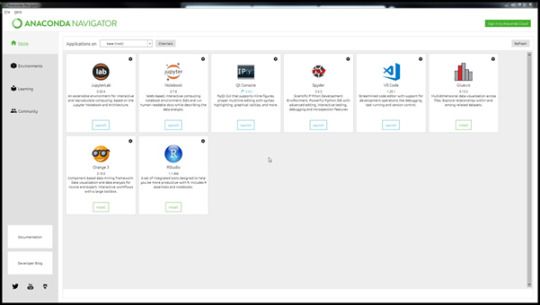
Now, you have successfully installed Anaconda on your system and it is ready to run. You can open the Anaconda Navigator and find other tools like Jupyter Notebook and Spyder IDE.
Once we have installed Anaconda, we will now move on to one of the most important components of the Python landscape, i.e. Python Libraries.
Note: Anaconda provides support for Linux as well as macOS. The installation details for the OS are provided on the official website in detail.
Libraries in Python
Libraries are a collection of reusable modules or functions which can be directly used in our code to perform a certain function without the necessity to write a code for the function. As mentioned earlier, Python has a huge collection of libraries which can be used for various functionalities like computing, machine learning, visualizations, etc. However, we will talk about the most relevant libraries required for coding trading strategies before actually getting started with Python. We will be required to:
import financial data,
perform numerical analysis,
build trading strategies,
plot graphs, and
perform backtesting on data.
For all these functions, here are a few most widely used libraries:
NumPy – NumPy or NumericalPy, is mostly used to perform numerical computing on arrays of data. The array is an element which contains a group of elements and we can perform different operations on it using the functions of NumPy.
Pandas – Pandas is mostly used with DataFrame, which is a tabular or a spreadsheet format where data is stored in rows and columns. Pandas can be used to import data from Excel and CSV files directly into the Python code and perform data analysis and manipulation of the tabular data.
Matplotlib – Matplotlib is used to plot 2D graphs like bar charts, scatter plots, histograms etc. It consists of various functions to modify the graph according to our requirements too.
TA-Lib – TA-Lib or Technical Analysis library is an open-source library and is extensively used to perform technical analysis on financial data using technical indicators such as RSI (Relative Strength Index), Bollinger bands, MACD etc. It not only works with Python but also with other programming languages such as C/C++, Java, Perl etc. Here are some of the functions available in TA-Lib:
BBANDS - For Bollinger Bands,
AROONOSC - For Aroon Oscillator,
MACD - For Moving Average Convergence/Divergence,
RSI - For Relative Strength Index.
Read about more such functions here.
Zipline – Zipline is a Python library for trading applications that power the Quantopian service mentioned above. It is an event-driven system that supports both backtesting and live trading.
These are but a few of the libraries which you will be using as you start using Python to perfect your trading strategy. To know about the myriad number of libraries in more detail, you can browse through this blog on Popular Python Trading platforms.
How to import data to Python?
This is one of the most important questions which needs to be answered before getting started with Python trading, as without data there is nothing you can go ahead with. Financial data is available on various online websites. This data is also called as time-series data as it is indexed by time (the timescale can be monthly, weekly, daily, 5 minutely, minutely, etc.). Apart from that, we can directly upload data from Excel sheets too which are in CSV format, which stores tabular values and can be imported to other files and codes. Now, we will learn how to import both time-series data and data from CSV files through the examples given below.
Importing Time Series Data
Here’s an example on how to import time series data from Yahoo finance along with the explanation of the command in the comments:
Note: In Python, we can add comments by adding a ‘#’ symbol at the start of the line.
To fetch data from Yahoo finance, you need to first pip install yfinance.
!pip install yfinance
You can fetch data from Yahoo finance using the download method.
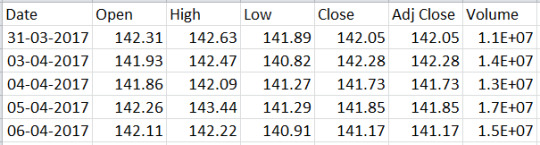
# Import yfinance import yfinance as yf # Get the data for stock Facebook from 2017-04-01 to 2019-04-30 data = yf.download('AAPL', start="2017-04-01", end="2019-04-30") # Print the first five rows of the data data.head()
Output:

Now, let’s look at another example where we can import data from an existing CSV file:
# Import pandas import pandas as pd # Read data from csv file data = pd.read_csv('FB.csv') data.head()
Creating a trading strategy and backtesting in Python
One of the simplest trading strategies involves Moving averages. But before we dive right into the coding part, we shall first discuss the mechanism on how to find different types of moving averages and then finally move on to one moving average trading strategy which is moving average convergence divergence, or in short, MACD. Let’s start with a basic understanding of moving averages.
What are Moving Averages?
Moving Average also called Rolling average, is the mean or average of the specified data for a given set of consecutive periods. As new data becomes available, the mean of the data is computed by dropping the oldest value and adding the latest one. So, in essence, the mean or average is rolling along with the data, and hence the name ‘Moving Average’. An example of calculating the simple moving average is as follows: Let us assume a window of 10, ie n = 10
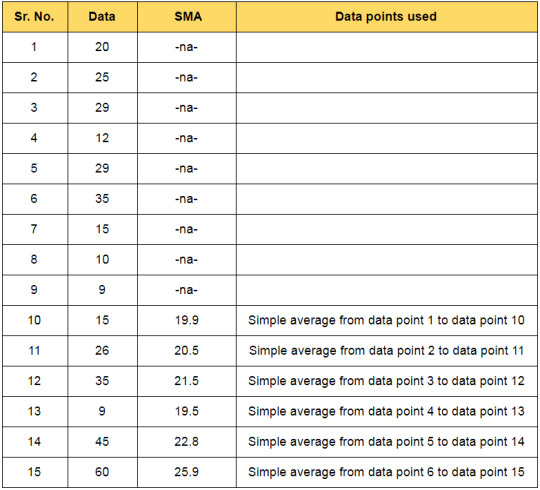
In the financial market, the price of securities tends to fluctuate rapidly and as a result, when we plot the graph of the price series, it is very difficult to predict the trend or movement in the price of securities. In such cases moving average will be helpful as it smoothens out the fluctuations, enabling traders to predict movement easily. Slow Moving Averages: The moving averages with longer durations are known as slow-moving averages as they are slower to respond to a change in trend. This will generate smoother curves and contain lesser fluctuations. Fast Moving Averages: The moving averages with shorter durations are known as fast-moving averages and are faster to respond to a change in trend.
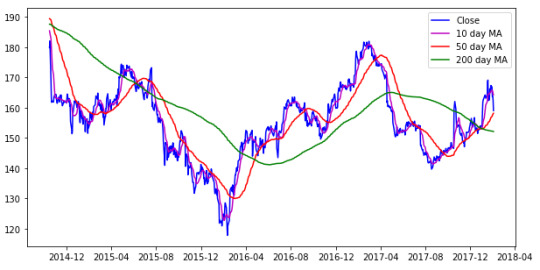
Consider the chart shown above, it contains:
the closing price of a stock IBM (blue line),
the 10-day moving average (magnum line),
the 50-day moving average (red line) and
the 200-day moving average (green line).
It can be observed that the 200-day moving average is the smoothest and the 10-day moving average has the maximum number of fluctuations. Going further, you can see that the 10-day moving average line is a bit similar to the closing price graph.
Types of Moving Averages
There are three most commonly used types of moving averages, the simple, weighted and the exponential moving average. The only noteworthy difference between the various moving averages is the weights assigned to data points in the moving average period. Let’s understand each one in further detail:
Simple Moving Average (SMA)
A simple moving average (SMA) is the average price of a security over a specific period of time. The simple moving average is the simplest type of moving average and calculated by adding the elements and dividing by the number of time periods. All elements in the SMA have the same weightage. If the moving average period is 10, then each element will have a 10% weightage in the SMA. The formula for the simple moving average is given below:
SMA = Sum of data points in the moving average period / Total number of periods
Exponential Moving Average (EMA)
The logic of exponential moving average is that latest prices have more bearing on the future price than past prices. Thus, more weight is given to the current prices than to the historic prices. With the highest weight to the latest price, the weights reduce exponentially over the past prices. This makes the exponential moving average quicker to respond to short-term price fluctuations than a simple moving average. The formula for the exponential moving average is given below:
EMA = (Closing price - EMA*(previous day)) x multiplier + EMA*(previous day)
Weightage multiplier = 2 / (moving average period +1)
Weighted Moving Average (WMA)
The weighted moving average is the moving average resulting from the multiplication of each component with a predefined weight. The exponential moving average is a type of weighted moving average where the elements in the moving average period are assigned an exponentially increasing weightage. A linearly weighted moving average (LWMA), generally referred to as weighted moving average (WMA), is computed by assigning a linearly increasing weightage to the elements in the moving average period. Now that we have an understanding of moving average and their different types, let’s try to create a trading strategy using moving average.
Moving Average Convergence Divergence (MACD)
Moving Average Convergence Divergence or MACD was developed by Gerald Appel in the late seventies. It is one of the simplest and effective trend-following momentum indicators. In MACD strategy, we use two series, MACD series which is the difference between the 26-day EMA and 12-day EMA and signal series which is the 9 day EMA of MACD series. We can trigger the trading signal using MACD series and signal series.
When the MACD line crosses above the signal line, then it is recommended to buy the underlying security.
When the MACD line crosses below the signal line, then a signal to sell is triggered.
Implementing the MACD strategy in Python
Import the necessary libraries and read the data
# Import pandas import pandas as pd # Import matplotlib import matplotlib.pyplot as plt plt.style.use('ggplot') # Read the data data = pd.read_csv('FB.csv', index_col=0) data.index = pd.to_datetime(data.index, dayfirst=True) # Visualise the data plt.figure(figsize=(10,5)) data['Close'].plot(figsize=(10,5)) plt.legend() plt.show()

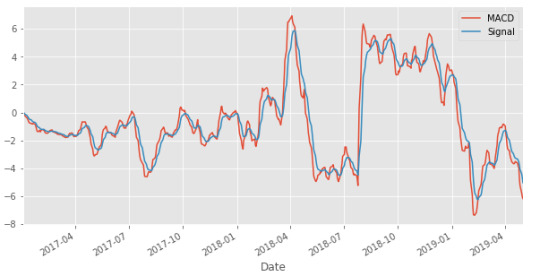
Calculate and plot the MACD series which is the difference 26-day EMA and 12-day EMA and signal series which is 9 day EMA of the MACD series.
# Calculate exponential moving average data['12d_EMA'] = data.Close.ewm(span=12).mean() data['26d_EMA'] = data.Close.ewm(span=26).mean() data[['Close','12d_EMA','26d_EMA']].plot(figsize=(10,5)) plt.show()

# Calculate MACD data['MACD'] = data['26d_EMA'] - data['12d_EMA'] # Calculate Signal data['Signal'] = data.MACD.ewm(span=9).mean() data[['MACD','Signal']].plot(figsize=(10,5)) plt.show()
Create a trading signal When the value of MACD series is greater than signal series then buy, else sell.
# Import numpy import numpy as np # Define Signal data['trading_signal'] = np.where(data['MACD'] > data['Signal'], 1, -1)
Create and calculate the strategy return
# Calculate Returns data['returns'] = data.Close.pct_change() # Calculate Strategy Returns data['strategy_returns'] = data.returns * data.trading_signal.shift(1) # Calculate Cumulative Returns cumulative_returns = (data.strategy_returns + 1).cumprod()-1 # Plot Strategy Returns cumulative_returns.plot(figsize=(10,5)) plt.legend() plt.show()
Evaluation of a trading strategy
So far, we have created a trading strategy as well as backtested it on historical data. But does this mean it is ready to be deployed in the live markets? Well, before we make our strategy live, we should understand its effectiveness, or in simpler words, the potential profitability of the strategy. While there are many ways to evaluate a trading strategy, we will focus on the following,
Annualised return,
Annualised volatility, and
Sharpe ratio.
Let’s understand them in detail as well as try to evaluate our own strategy based on these factors:
1. Annualised Return or Compound Annual Growth Rate (CAGR)
To put it simply, CAGR is the rate of return of your investment which includes the compounding of your investment. Thus it can be used to compare two strategies and decide which one suits your needs. Calculating CAGR CAGR can be easily calculated with the following formula:
CAGR = [(Final value of investment /Initial value of investment)^(1/number of years)] - 1
For example, we invest in 2000 which grows to 4000 in the first year but drops to 3000 in the second year. Now, if we calculate the CAGR of the investment, it would be as follows:
CAGR = (3000/2000)^(½) - 1 = 0.22 = 22%
For our strategy, we will try to calculate the daily returns first and then calculate the CAGR. The code, as well as the output, is given below: In[]
# Total number of trading days in a year is 252 trading_days = 252 # Calculate CAGR by multiplying the average daily returns with number of trading days annual_returns = ((1 + data.returns.mean())**(trading_days) - 1)*100 'The CAGR is %.2f%%' % annual_returns
Out []:
'The CAGR is 30.01%'
2. Annualised Volatility
Before we define annualised volatility, let’s understand the meaning of volatility. A stock’s volatility is the variation in the stock price over a period of time. For the strategy, we are using the following formula:
Annualised Volatility = square root (trading days) * square root (variance)
The code, as well as the output, is given below: In[]
# Calculate the annualised volatility annual_volatility = data.returns.std() * np.sqrt(trading_days) * 100 'The annualised volatility is %.2f%%' % annual_volatility
Out []:
'The annualised volatility is 30.01%'
3. Sharpe Ratio
Sharpe Ratio is basically used by investors to understand the risk taken in comparison to the risk-free investments, such as treasury bonds etc. The sharpe ratio can be calculated in the following manner:
Sharpe ratio = [r(x) - r(f)] / δ(x)
Where,
r(x) = annualised return of investment x r(f) = Annualised risk free rate δ(x) = Standard deviation of r(x)
The Sharpe Ratio should be high in case of similar or peers. The code, as well as the output, is given below: In[]
# Assume the annual risk-free rate is 6% risk_free_rate = 0.06 daily_risk_free_return = risk_free_rate/trading_days # Calculate the excess returns by subtracting the daily returns by daily risk-free return excess_daily_returns = data.returns - daily_risk_free_return # Calculate the sharpe ratio using the given formula sharpe_ratio = (excess_daily_returns.mean() / excess_daily_returns.std()) * np.sqrt(trading_days) 'The Sharpe ratio is %.2f' % sharpe_ratio
Out[]:
'The Sharpe ratio is 0.68'
Python Books and References
Python Basics: With Illustrations From The Financial Markets
A Byte of Python
A Beginner’s Python Tutorial
Python Programming for the Absolute Beginner, 3rd Edition
Python for Data Analysis, By Wes McKinney
Conclusion
Python is widely used in the field of machine learning and now trading. In this article, we have covered all that would be required for getting started with Python. It is important to learn it so that you can code your own trading strategies and test them. Its extensive libraries and modules smoothen the process of creating machine learning algorithms without the need to write huge codes. To start learning Python and code different types of trading strategies, you can select the “Algorithmic Trading For Everyone” learning track on Quantra. Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.
Trading via QuantInsti http://bit.ly/2Zi7kP2 August 26, 2019 at 04:14AM
0 notes
Text
Brands can better understand users on third-party sites by using a keyword overlap analysis
If you are a manufacturer selling on your own site as well as on retail partners, it is likely you don’t have visibility into who is buying your products or why they buy beyond your own site. More importantly, you probably don’t have enough insights to improve your marketing messaging.
One technique you can use to identify and understand your users buying on third-party websites is to track your brand through organic search. You can then compare the brand searches on your site and the retail partner, see how big the overlap is, how much of the overlapping keywords you rank above the retailer and vice versa. More importantly, you can see if you are appealing to different audiences or competing for the same ones. Armed with these new insights, you could restructure your marketing messaging to unlock new audiences you didn’t tap into before.
In previous articles, I’ve covered several useful data blending examples, but in this one, we will do something different. We will do a deeper dive into just one data blending example and perform what I call a cross-site branded keyword overlap analysis. As you will learn below, this type of analysis will help us understand your users buying on third-party retailer partners.
In the Venn diagram above, you can see an example of visualization we will put together in this article. It represents the number of overlapping keywords in organic search for the brand “Tommy Hilfiger” between their main brand site and Macy’s, a retail partner.
We recently had to perform this analysis for one of our clients and our findings surprised us. We discovered that with 60% of our client’s organic SEO traffic coming from branded searches, as much as 30% of those searches were captured by four retailer partners that also sell their products.
Armed with this evidence and with the knowledge that selling through their retail partners still made business sense, we provided guidance on how to improve their brand searches so they can compete more effectively, and change their messaging to appeal to a different customer than the one that buys from the retailers.
After my team conducted this analysis manually and I saw how valuable it is, I set out to automate the whole process in Python so we could easily reproduce it for all our manufacturing clients. Let me share the code snippets I wrote here and walk you over their use.
Pulling branded organic search keywords
I am using the Semrush API to collect the branded keywords from their service. I created a function to take their response and return a pandas data frame. This function simplifies the process of collecting data for multiple domains.
Here is the code to get organic searches for “Tommy Hilfiger” going to Macy’s.
Here is the code to get organic searches for “Tommy Hilfiger” going to Tommy Hilfiger directly.
Visualizing the branded keyword overlap
After we pull the searches for “Tommy Hilfiger” from both sites, we want to understand the size of the overlap. We accomplish this in the following lines of code:
We can quickly see that the overlap is significant, with 4601 keywords in common, 515 unique to Tommy Hilfiger, and 125 unique to Macy’s.
Here is the code to visualize this overlap as the Venn diagram illustrated above.
Who ranks better for the overlapping keywords?
The most logical next question you would want to ask is that given how significant the overlap is, who commands more higher rankings for those. How can we figure this out? With data blending of course!
First, as we learned in my first data blending article, we will merge the two data frames, and we will use an inner join to keep only the keywords common in the two sets.
When we merge data frames and they have the same columns, they are repeated and the first columns include _x at the end and the second one includes _y. So, Macy’s columns end with _x.
Here is how we create a new data frame with the overlapping branded keywords where Macy’s ranks higher.
Here is the corresponding data frame where Tommy Hilfiger ranks higher.
Here we can see that while the overlap is big, Tommy ranks higher for many more branded keywords than Macy’s (3,173 vs. 1,075). So, is Tommy doing better? Not quite!
As you remember, we also pulled traffic numbers from the API. In the next snippet of code, we will check which keywords are pulling more traffic.
Surprisingly, we see that, while Macy’s performs better for fewer keywords than Tommy Hilfiger, when we add up the traffic, Macy’s attracts more visitors (75,026 vs. 66,415).
As you can see, sweating the details matters a lot in this type of analysis!
How different are the audiences
Finally, let’s use the branded keywords unique to each site to learn any differences in the audiences that visit each site. We will simply strip the branded phrase from the keywords and create word clouds to understand them better. When we remove the branded phrase “Tommy Hilfiger,” we are left with the additional qualifiers that users use to indicate their intention.
I created a function to create and display the word clouds. Here is the code:
Here is the word cloud with the most popular words left after you remove the phrase “Tommy Hilfiger” from Macy’s keywords.
Here is the corresponding word cloud when you do the same for the Tommy Hilfiger ones.
The main difference I see is people looking for Tommy Hilfiger products in Macy’s have specific products in mind, like boots and curtains, while when it comes to the brand site, people primarily have the outlets in mind. This might be an indicator that they intend to visit the store vs. trying to purchase online. This may also indicate that people going to brand site are bargain hunters while the ones going to Macy’s might not be. These are very interesting and powerful insights!
Given these insights, Tommy Hilfiger could review the SERPS and compare the difference in the messaging between Macy’s and their brand site and adjust it to appeal to their unique audience’s interests.
The post Brands can better understand users on third-party sites by using a keyword overlap analysis appeared first on Search Engine Land.
Brands can better understand users on third-party sites by using a keyword overlap analysis published first on https://likesfollowersclub.tumblr.com/
0 notes
Text
Brands can better understand users on third-party sites by using a keyword overlap analysis
If you are a manufacturer selling on your own site as well as on retail partners, it is likely you don’t have visibility into who is buying your products or why they buy beyond your own site. More importantly, you probably don’t have enough insights to improve your marketing messaging.
One technique you can use to identify and understand your users buying on third-party websites is to track your brand through organic search. You can then compare the brand searches on your site and the retail partner, see how big the overlap is, how much of the overlapping keywords you rank above the retailer and vice versa. More importantly, you can see if you are appealing to different audiences or competing for the same ones. Armed with these new insights, you could restructure your marketing messaging to unlock new audiences you didn’t tap into before.
In previous articles, I’ve covered several useful data blending examples, but in this one, we will do something different. We will do a deeper dive into just one data blending example and perform what I call a cross-site branded keyword overlap analysis. As you will learn below, this type of analysis will help us understand your users buying on third-party retailer partners.
In the Venn diagram above, you can see an example of visualization we will put together in this article. It represents the number of overlapping keywords in organic search for the brand “Tommy Hilfiger” between their main brand site and Macy’s, a retail partner.
We recently had to perform this analysis for one of our clients and our findings surprised us. We discovered that with 60% of our client’s organic SEO traffic coming from branded searches, as much as 30% of those searches were captured by four retailer partners that also sell their products.
Armed with this evidence and with the knowledge that selling through their retail partners still made business sense, we provided guidance on how to improve their brand searches so they can compete more effectively, and change their messaging to appeal to a different customer than the one that buys from the retailers.
After my team conducted this analysis manually and I saw how valuable it is, I set out to automate the whole process in Python so we could easily reproduce it for all our manufacturing clients. Let me share the code snippets I wrote here and walk you over their use.
Pulling branded organic search keywords
I am using the Semrush API to collect the branded keywords from their service. I created a function to take their response and return a pandas data frame. This function simplifies the process of collecting data for multiple domains.
Here is the code to get organic searches for “Tommy Hilfiger” going to Macy’s.
Here is the code to get organic searches for “Tommy Hilfiger” going to Tommy Hilfiger directly.
Visualizing the branded keyword overlap
After we pull the searches for “Tommy Hilfiger” from both sites, we want to understand the size of the overlap. We accomplish this in the following lines of code:
We can quickly see that the overlap is significant, with 4601 keywords in common, 515 unique to Tommy Hilfiger, and 125 unique to Macy’s.
Here is the code to visualize this overlap as the Venn diagram illustrated above.
Who ranks better for the overlapping keywords?
The most logical next question you would want to ask is that given how significant the overlap is, who commands more higher rankings for those. How can we figure this out? With data blending of course!
First, as we learned in my first data blending article, we will merge the two data frames, and we will use an inner join to keep only the keywords common in the two sets.
When we merge data frames and they have the same columns, they are repeated and the first columns include _x at the end and the second one includes _y. So, Macy’s columns end with _x.
Here is how we create a new data frame with the overlapping branded keywords where Macy’s ranks higher.
Here is the corresponding data frame where Tommy Hilfiger ranks higher.
Here we can see that while the overlap is big, Tommy ranks higher for many more branded keywords than Macy’s (3,173 vs. 1,075). So, is Tommy doing better? Not quite!
As you remember, we also pulled traffic numbers from the API. In the next snippet of code, we will check which keywords are pulling more traffic.
Surprisingly, we see that, while Macy’s performs better for fewer keywords than Tommy Hilfiger, when we add up the traffic, Macy’s attracts more visitors (75,026 vs. 66,415).
As you can see, sweating the details matters a lot in this type of analysis!
How different are the audiences
Finally, let’s use the branded keywords unique to each site to learn any differences in the audiences that visit each site. We will simply strip the branded phrase from the keywords and create word clouds to understand them better. When we remove the branded phrase “Tommy Hilfiger,” we are left with the additional qualifiers that users use to indicate their intention.
I created a function to create and display the word clouds. Here is the code:
Here is the word cloud with the most popular words left after you remove the phrase “Tommy Hilfiger” from Macy’s keywords.
Here is the corresponding word cloud when you do the same for the Tommy Hilfiger ones.
The main difference I see is people looking for Tommy Hilfiger products in Macy’s have specific products in mind, like boots and curtains, while when it comes to the brand site, people primarily have the outlets in mind. This might be an indicator that they intend to visit the store vs. trying to purchase online. This may also indicate that people going to brand site are bargain hunters while the ones going to Macy’s might not be. These are very interesting and powerful insights!
Given these insights, Tommy Hilfiger could review the SERPS and compare the difference in the messaging between Macy’s and their brand site and adjust it to appeal to their unique audience’s interests.
The post Brands can better understand users on third-party sites by using a keyword overlap analysis appeared first on Search Engine Land.
Brands can better understand users on third-party sites by using a keyword overlap analysis published first on https://likesandfollowersclub.weebly.com/
0 notes
Text
May 26, 2020 at 10:00PM - The Complete Python Data Science Bundle (96% discount) Ashraf
The Complete Python Data Science Bundle (96% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
It’s no secret that data scientists stand to make a pretty penny in today’s data-driven world; but if you’re keen on becoming one, you’ll need to master the appropriate tools. Pandas is one of the most popular of the Python data science libraries for working with mounds of data. By expressing data in a tabular format, Pandas makes it easy to perform data cleaning, aggregations and other analyses. Built around hands-on demos, this course will walk you through using Pandas and what it can do as you take on series, data frames, importing/exporting data, and more.
Access 23 lectures & 2.5 hours of content 24/7
Explore Panda’s built-in functions for common data manipulation techniques
Learn how to work with data frames & manage data
Deepen your understanding w/ example-driven lessons
Today’s companies collect and utilize a staggering amount of data to guide their business decisions. But, it needs to be properly cleaned and organized before it can be put to use. Enter NumPy, a core library in the Python data science stack used by data science gurus to wrangle vast amounts of multidimensional data. This course will take you through NumPy’s basic operations, universal functions, and more as you learn from hands-on examples.
Access 27 lectures & 2.5 hours of content 24/7
Familiarize yourself w/ NumPy’s basic operations & universal functions
Learn how to properly manage data w/ hands-on examples
Validate your training w/ a certificate of completion
From tech to medicine and finance, data plays a pivotal role in guiding today’s businesses. But, it needs to be properly broken down and visualized before you can get any sort of actionable insights. That’s where Seaborn comes into play. Designed for enhanced data visualization, this Python-based library helps bridge the gap between vast swathes of data and the valuable insights they contain. This course acts as your Seaborne guide, walking you through what it can do and how you can use it to display information, find relationships, and much more.
Access 16 lectures & 1.5 hours of content 24/7
Familiarize yourself w/ Seaborn via hands-on examples
Discover Seaborn’s enhanced data visualization capabilities
Explore histograms, linear relationships & more visualization concepts
Before a data scientist can properly analyze their data, they must first visualize it and understand any relationships that might exist in the information. To this end, many data professionals use Matplotlib, an industry-favorite Python library for visualizing data. Highly customizable and packed with powerful features for building graphs and plots, Matplotlib is an essential tool for any aspiring data scientist, and this course will show you how it ticks.
Access 30 lectures & 3 hours of content 24/7
Explore the anatomy of a Matplotlib figure & its customizable parts
Dive into figures, axes, subplots & more components
Learn how to draw statistical insights from data
Understand different ways of conveying statistical information
One of the most popular data analytics engines out there, Spark has become a staple in many a data scientist’s toolbox; and the latest version, Spark 2.x, brings more efficient and intuitive features to the table. Jump into this comprehensive course, and you’ll learn how to better analyze mounds of data, extract valuable insights, and more with Spark 2.x. Plus, this course comes loaded with hands-on examples to refine your knowledge, as you analyze data from restaurants listed on Zomato and churn through historical data from the Olympics and the FIFA world cup!
Access 27 lectures & 3 hours of content 24/7
Explore what Spark 2.x can do via hands-on projects
Learn how to analyze data at scale & extract insights w/ Spark transformations and actions
Deepen your understanding of data frames & Resilient Distributed Datasets
You don’t need to be a programming prodigy to get started in data science. Easy to use and highly accessible, Plotly is library in Python that lets you create complex plots and graphs with minimal programming know-how. From creating basic charts to adding motion to your visualizations, this course will walk you through the Plotly essentials with hands-on examples that you can follow.
Access 27 lectures & 2 hours of content 24/7
Learn how to build line charts, bar charts, histograms, pie charts & other basic visualizations
Explore visualizing data in more than two dimensions
Discover how to add motion to your graphs
Work w/ plots on your local machine or share them via the Plotly Cloud
In addition to handling vast amounts of batch data, Spark has extremely powerful support for continuous applications, or those with streaming data that is constantly updated and changes in real-time. Using the new and improved Spark 2.x, this course offers a deep dive into stream architectures and analyzing continuous data. You’ll also follow along a number of real-world examples, like analyzing data from restaurants listed on Zomato and real-time Twitter data.
Access 36 lectures & 2.5 hours of content 24/7
Familiarize yourself w/ Spark 2.x & its support for continuous applications
Learn how to analyze data from real-world streams
Analyze data from restaurants listed on Zomato & real-time Twitter data
More companies are using the power of deep learning and neural networks to create advanced AI that learns on its own. From speech recognition software to recommendation systems, deep learning frameworks, like PyTorch, make creating these products easier. Jump in, and you’ll get up to speed with PyTorch and its capabilities as you analyze a host of real-world datasets and build your own machine learning models.
Access 41 lectures & 3.5 hours of content 24/7
Understand neurons & neural networks and how they factor into machine learning
Explore the basic steps involved in training a neural network
Familiarize yourself w/ PyTorch & Python 3
Analyze air quality data, salary data & more real-world datasets
Fast, scalable, and packed with an intuitive API for machine learning, Apache MXNet is a deep learning framework that makes it easy to build machine learning applications that learn quickly and can run on a variety of devices. This course walks you through the Apache MXNet essentials so you can start creating your own neural networks, the building blocks that allow AI to learn on their own.
Access 31 lectures & 2 hours of content 24/7
Explore neurons & neural networks and how they factor into machine learning
Walk through the basic steps of training a neural network
Dive into building neural networks for classifying images & voices
Refine your training w/ real-world examples & datasets
Python is a general-purpose programming language which can be used to solve a wide variety of problems, be they in data analysis, machine learning, or web development. This course lays a foundation to start using Python, which considered one of the best first programming languages to learn. Even if you’ve never even thought about coding, this course will serve as your diving board to jump right in.
Access 28 lectures & 3 hours of content 24/7
Gain a fundamental understanding of Python loops, data structures, functions, classes, & more
Learn how to solve basic programming tasks
Apply your skills confidently to solve real problems
Classification models play a key role in helping computers accurately predict outcomes, like when a banking program identifies loan applicants as low, medium, or high credit risks. This course offers an overview of machine learning with a focus on implementing classification models via Python’s scikit-learn. If you’re an aspiring developer or data scientist looking to take your machine learning knowledge further, this course is for you.
Access 17 lectures & 2 hours of content 24/7
Tackle basic machine learning concepts, including supervised & unsupervised learning, regression, and classification
Learn about support vector machines, decision trees & random forests using real data sets
Discover how to use decision trees to get better results
Deep learning isn’t just about helping computers learn from data—it’s about helping those machines determine what’s important in those datasets. This is what allows for Tesla’s Model S to drive on its own and for Siri to determine where the best brunch spots are. Using the machine learning workhorse that is TensorFlow, this course will show you how to build deep learning models and explore advanced AI capabilities with neural networks.
Access 62 lectures & 8.5 hours of content 24/7
Understand the anatomy of a TensorFlow program & basic constructs such as graphs, tensors, and constants
Create regression models w/ TensorFlow
Learn how to streamline building & evaluating models w/ TensorFlow’s estimator API
Use deep neural networks to build classification & regression models
from Active Sales – SharewareOnSale https://ift.tt/2OYNcYd https://ift.tt/eA8V8J via Blogger https://ift.tt/3c6qFUW #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
Mars Craters - Data Aggregation and Frequency Distribution
Introduction to blog
Purpose of this blog is to post my assignment work related to the course “Data Management and Visualization” offered by Wesleyan University through Coursera. This post is for Week 2 assignment which is broadly focused towards writing program and performing data analysis targeting frequency distribution and aggregation as applicable.
Area of research and Data processing
Area of research selected in Week 1 was Mars Crater’s study. Programming was done in Python and code is published in next section under “Python Code” but below is explanation of steps taken towards data aggregation.
1. Loaded initial raw data to “pandas” data frame.
2. Based on hypothesis identified during week 1 assignment below variables were chosen and aggregated.
a. Crater size – New column inserted in data frame to categorize craters in multiples of 10. Example Cat 1 = size <10, Cat 2 = 10 < size > 20 and so on.
b. Morphology 1 – Categories were restricted to first 5 letters of significance based on nomenclature.
c. Morphology 2 – Categories were restricted to hummocky and Smooth type. Other secondary classification was ignored as they only depict patterns.
d. Number of Layers. Even though this is corelated with Morphology 1. We considered this data as this variable give more classification upto Layer 5, whereas Morphology 1 considers 3 and above as multiple layers.
3. Frequency distribution data generated using code depicted in Course. Findings are summarized in Inference section of this blog.
Python Code
# -*- coding: utf-8 -*-
"""
Created on Mon May 25 15:33:27 2020
@author: Chandrakant Padhee
"""
#BELOW CODES IMPORT NECESSARY LIBRARIES - PANDAS AND NUMPY
import pandas #importing pandas library
import numpy #importing numpy library
#BUG FIX TO REMOVE RUNTIME ERROR
pandas.set_option('display.float_format',lambda x:'%f'%x)
#READING DATA FROM CSV SOURCE FILE AND IMPORT THEM TO DATAFRAME data_mars
data_mars = pandas.read_csv('marscrater_pds.csv',low_memory=False)
data_mars.columns = map(str.upper,data_mars.columns)
#BELOW CODE ADDS CATEGORIZATION OF CRATER SIZE IN MULTIPLES OF 10KM.
#EXAMPLE 1 REPRESENTS CRATER SIZE LESS THAN 10KM AND 2 REPRESENTS SIZE BETWEEN 10KM to 20KM AND SO ON.
data_mars['Crater_Size_Cat'] = data_mars['DIAM_CIRCLE_IMAGE']//10 + 1
#BELOW CODE MODIFIES MMORPHOLOGY_EJECTA_2 DATA TO HUMMOCKY AND SMOOTH
data_mars['Morph_2'] = data_mars['MORPHOLOGY_EJECTA_2'].str[:2]
#BELOW CODE MODIFIES MMORPHOLOGY_EJECTA_1 DATA TO RESTRICT TO SIMPLE LAYERS NOMENCLATURE
data_mars['Morph_1'] = data_mars['MORPHOLOGY_EJECTA_1'].str[:5]
#AS TARGET IS TO STUDY MORPHOLOGICAL DATA FROM GLOBAL DATASET,
#WE CREATE NEW DATA FRAME REMOVING ALL THE ROWS HAVING "NUMBER_LAYERS" = 0
#STORE NEW DATA UNDER NEW DATA FRAME data_mars_mod
data_mars_mod = data_mars[data_mars.NUMBER_LAYERS!= 0]
#BELOW CODE IS TO CALCULATE FREQUENCY DISTRIBUTION OF "NUMBER OF LAYERS" IN TERMS OF COUNTS AND PERCENTAGES
c1 = data_mars_mod["NUMBER_LAYERS"].value_counts(sort=False)
p1 = data_mars_mod["NUMBER_LAYERS"].value_counts(sort=False, normalize=True)*100
#BELOW CODE IS TO CALCULATE FREQUENCY DISTRIBUTION OF "MORPHOLOGY CHARECTERISTICS 1" IN TERMS OF COUNTS AND PERCENTAGES
c2 = data_mars_mod["Morph_1"].value_counts(sort=False)
p2 = data_mars_mod["Morph_1"].value_counts(sort=False, normalize=True)*100
#BELOW CODE IS TO CALCULATE FREQUENCY DISTRIBUTION OF "MORPHOLOGY CHARECTERISTICS 2" IN TERMS OF COUNTS AND PERCENTAGES
c3 = data_mars_mod["Morph_2"].value_counts(sort=False)
p3 = data_mars_mod["Morph_2"].value_counts(sort=False, normalize=True)*100
#BELOW CODE IS TO CALCULATE FREQUENCY DISTRIBUTION OF "AGGREGATED CRATER SIZES" IN TERMS OF COUNTS AND PERCENTAGES
c4 = data_mars_mod["Crater_Size_Cat"].value_counts(sort=False)
p4 = data_mars_mod["Crater_Size_Cat"].value_counts(sort=False, normalize=True)*100
#BELOW CODES PRINTS OUT THE OUTPUT DISCTRIBUTION OF NUMBER OF LAYERS AND EJECTA PROFILES
print('Number of counts of Craters with different number of layers are as below')
print(c1)
print('Percentages of Craters with different number of layers are as below ')
print(p1)
print('Number of counts with different Morphology ejecta 1 charecteristics for craters are as below - Ex SLERS (Single Layer Ejecta / Rampant/Circular')
print(c2)
print('Percentages of different Morphology ejecta 1 charecteristics for craters are as below - Ex SLERS (Single Layer Ejecta / Rampant/Circular' )
print(p2)
print('Number of counts with different Morphology ejecta 2 charecteristics for craters are as below - H = Hummocky and S = Smooth')
print(c3)
print('Number of counts with different Morphology ejecta 2 charecteristics for craters are as below - H = Hummocky and S = Smooth')
print(p3)
print('Counts of Crater size in multiples of 10KM are as below')
print(c4)
print('Percentages of Crater size in multiples of 10KM are as below')
print(p4)
Output Frequency Tables
VARIABLE 1 – LAYERS OF CRATERS
Number of counts of Craters with different number of layers are as below
1 15467
2 3435
3 739
4 85
5 5
Percentages of Craters with different number of layers are as below
1 78.389337
2 17.409153
3 3.745375
4 0.430794
5 0.025341
VARIABLE 2 – MORPHOLOGY_EJECTA_1
Number of counts with different Morphology ejecta 1 characteristics for craters are as below - Ex SLERS (Single Layer Ejecta / Rampant/Circular)
SLErS 1
MLERC 24
SLERC 1290
DLSPC 1
DLEPC 505
Rd/SP 1
RD/SL 1
Rd/SL 1298
SLERS 5130
MLERS 492
MLEPS 43
Rd/DL 637
Rd/ML 240
SLEPS 5053
DLEPS 633
DLERS 1244
SLEPC 2678
DLERC 393
MLEPC 22
SLEPd 44
DLEPd 1
Percentages of different Morphology ejecta 1 characteristics for craters are as below - Ex SLERS (Single Layer Ejecta / Rampant/Circular)
SLErS 0.005068
MLERC 0.121636
SLERC 6.537935
DLSPC 0.005068
DLEPC 2.559424
Rd/SP 0.005068
RD/SL 0.005068
Rd/SL 6.578481
SLERS 25.999696
MLERS 2.493538
MLEPS 0.217931
Rd/DL 3.228422
Rd/ML 1.216360
SLEPS 25.609447
DLEPS 3.208150
DLERS 6.304800
SLEPC 13.572551
DLERC 1.991790
MLEPC 0.111500
SLEPd 0.222999
DLEPd 0.005068
VARIABLE 3 – MORPHOLOGY_EJECTA_2
Number of counts with different Morphology ejecta 2 characteristics for craters are as below - H = Hummocky and S = Smooth
Sm 5561
Hu 13912
HU 3
Number of counts with different Morphology ejecta 2 characteristics for craters are as below - H = Hummocky and S = Smooth
Sm 28.184076
Hu 70.508337
HU 0.015205
VARIABLE 4: CRATER SIZE (DIAMETER) IN MULTIPLES OF 10KM
Counts of Crater size in multiples of 10KM are as below
9.000000 1
4.000000 172
3.000000 618
2.000000 3404
1.000000 15463
6.000000 15
12.000000 1
8.000000 5
5.000000 46
7.000000 6
Percentages of Crater size in multiples of 10KM are as below
9.000000 0.005068
4.000000 0.871725
3.000000 3.132127
2.000000 17.252040
1.000000 78.369064
6.000000 0.076023
12.000000 0.005068
8.000000 0.025341
5.000000 0.233136
7.000000 0.030409
Inference:
Frequency distribution from above tables were generated after segregating data for which morphology information was available, hence rest of the rows were deleted in data frame. Above distribution reveals below details:
1. Most of the craters from segregated data are having One Layer (78%) or Two layers (17%) Rest small portion is distributed to Three, Four- and Five-layers Craters
2. This is also supplemented by Morphology_Ejecta_1 data but additional information received is most of craters under Single and Double layers have equal representation from Pancake Circular, Pancake Sinusal and Rampant Sinusal categories.
3. Morphology_Ejecta_2 reveal ejecta patters are mostly hummock type as compared to smooth profiles with 70:30 proportion
4. Lastly as far as size of craters is considered, most of them fall under less than 10KM category with 78% share.
Above information closely relates to correlation between layer dependent morphology vs crater size which was initial hypothesis. But this can only be proven after further analysis of data.
Summary
Purpose of initial post is hereby covered considering below points.
Writing programming code: Python was used to write code and same is presented under section “Python Code”
Display of Variables frequency table: This is covered under section “Output Frequency Table”
Description of frequency distribution: This is covered in “Inference Section”
0 notes
Text
python data vis, small and not-small victories, and a taste of ML
tl;dr - Check out the Jupyter notebook I created for finding the most annoying question in the Sister Survey, plus a few visualizations of answers to demographic questions.
Last week I wrote about my using my rudimentary Python scripting skills to explore the “Sister Survey,” which was a large survey administered to nearly 140,000 American women in Catholic ministry in 1967. A kind RC alum shared my post on MetaFilter, which lead to an absolutely amazing discussion, including a thorough explanation of the religious and historical context of the “most annoying question.” Definitely worth a read!
I noticed that two different commenters had some pretty specific requests!
“I'd love to see this redone as a Jupyter notebook.”
“It would be interesting to see what kinds of structure live in that data, e.g. factor analysis on the questions to see the more-or-less-independent areas of belief.”
The former I’d never done but seemed easy enough and the latter I’d never done and had absolutely no idea how to start, so I decided to cut the effort down the middle and create a Jupyter notebook with a few visualizations for demographic questions I found in the survey.
You can view it here.
Here are a few of the lessons I learned this week.
Wow, this whole ‘notebook’ thing is great.
This was the first time I’d worked with an iPython notebook, and it’s really hard to imagine going back to pure scripting. So many of the small annoyances that I struggled with while writing the original script - having to remember variable names and what was in them, accidentally re-running the portion that downloaded the responses, having to manually indent in code blocks - are handled so neatly in the notebook structure. The more I learn about programming, the more often this happens: finding a solution that makes life an order of magnitude more pleasant, that I somehow wasn’t using before even though I was technically aware of its existence. It always feels a little silly to recognize how inefficiently I was doing things before, though doing things that way provided its own learning opportunities too.
The switch from writing Python in the terminal to using a notebook was generally seamless, though I did find myself surprised on one occasion. I’d noticed the execution order flag next to the notebook inputs, and I’d noticed them incrementing as I ran blocks of code, but I hadn’t realized that exporting the notebook (or uploading it to a Python notebook viewer, like Anaconda Cloud), would preserve that run order.

What a powerful notion! I’m guessing this is particularly useful when working with data, since reproducibility is one of the hallmarks of good analysis.
When trivial things aren’t.
This was a really challenging week for me for reasons outside of RC. Emotional compartmentalization is a fool’s errand, though, so I mostly had to let myself deal with that - even when I would’ve much rather had my attention entirely focused on becoming a better programmer. When I encountered difficulties with what I assumed should be a very basic data visualization task, combined with my already dismal mood, my confidence bottomed out.
The gulf between my expectations for myself and my current performance was horrifying. I felt unsalvageable. Because I couldn’t immediately get some bar charts to display correctly.
Anyways, I kept going, because I didn’t have any better plans. And once I was able to clear my head enough to just do the damn thing, things came together. I felt better when I was finished, though I still had a lingering shame that it’d taken so long. (It didn’t take that long.)
I decided to post in the RC’s #victory channel, for three reasons - two good and one questionable:
I believe that it’s important to acknowledge and celebrate one’s wins.
Even so, I don’t ever do it for myself. So I need to practice if I want to live according to my principles.
It seemed funny to celebrate something so utterly banal, anyway.
The response was super heartening. 🙂

All the frustrating moments - when I couldn’t tell if I needed to be reading MatPlotLib’s documentation, or Pandas documentation, and how the two libraries might be interacting with each other - suddenly felt real and valid. I don’t know why I was so surprised at how much better this made me feel, but I was. Social creatures are strange!
The power of 5 minutes.
I mentioned earlier that I had absolutely no idea how to start a principal analysis, which I took to mean, “find out which questions are most important for determining a respondents overall position.” That might be a bit of an exaggeration, because I at least had a suspicion that some kind of clustering algorithm would be the right place to start.
Another big source of anxiety this week was the sense that I really wished I could answer this question, but that I didn’t have the skills or knowledge to do it. While I’m not so great at celebrating victories, I am thankfully at least marginally better at asking for help when I’m stuck. I asked around RC to see if any folks had experience implementing k-means in Python, but more broadly, if someone could help me talk through whether that was even the right approach for clustering respondents by their survey answers.
Fellow Winter 1 batcher Genevieve Hoffman, who has a background in creating data-art installations, came to my aid. I explained my goal and the data I had on hand, plus my central concern: is k-means even appropriate when the data you’re working with is essentially discrete and categorical (eg. multiple choice survey responses)? We both weren’t quite sure, so we started googling. The response was resoundingly: no, k-means relies on Euclidean distances for its clustering and therefore is not the right way to go.
Could I have gotten to this answer myself? Almost certainly! But doing the work to frame my concern in a way that another person could understand it, searching for an answer together, and digesting the results together - even over the course of a few minutes - was invaluable for both widening my perspective and reassuring me that my intuitions were worth listening to. Several of the responses we read suggested that another (much less widely used) algorithm would be more appropriate: k-modes.
At the time of that conversation I had pretty much resolved that I should give up on clustering for now and be satisfied with my bar charts. I found, however, that I am generally not great at giving up. (For better and for worse.) I read more about k-modes, mostly getting lost in the math, until it finally dawned on me: why don’t I just try to use this, for like, five minutes?
You can probably see where this is going.

Those are three possible clusters when running k-modes on survey respondents answers to the demographic questions. Each value in the centroids list corresponds to an answer to a question, specifically these questions:
Your age now
Number of years in congregation from first vows
What is your race
To which of the following groups do you consider your family to have belonged while you were growing up
To what religion did you belong while you were growing up
With which political group would you align yourself
You can see right away that some questions don’t matter. For example, pretty much everyone was white and had been Catholic before joining the ministry. And there are clearly correlations with how old the respondent was and the number of years they’d been in the congregation: younger respondents had taken their vows more recently.
The most interesting result was the last one, where it seems like there may be some relationship between age and years in the congregation and willingness to identify politically: the 6 response in the survey is “I do not consider myself in a political context” and the 2 response is “Liberal Democrat.”
Two important developments came out of this very, very quick exploration. Firstly, wow, going from “I can’t do it” to “it’s done” in such a brief amount of time really calls into question the accuracy of one’s sense of personal agency! And secondly, algorithms aren’t magic and it would take a lot more work before I felt comfortable making any claims stronger than “maybe something is happening here?”
I’m excited to work my way towards that point, but I am not there yet. Plus, I don’t have any deep understanding of Catholicism and religious history, which seems like it would be pretty darn helpful in this situation! If I’m going to be getting into data analysis through machine learning, I feel like it’d be a lot more responsible to start with a less complex (and less serious?) dataset.
1 note
·
View note
Text
5 Best Python Machine Learning IDEs
In this article we are going to discuss about best Python Machine Learning IDEs and will find out which one suits you according to your needs. Also we will be deciding what should be the system requirements and hardware configuration of our machine to run these IDEs smoothly without any lag. So without wasting a moment let us get straight to the point.
IDE (Integrated Development Environment)
As it is very much clear from the name itself what an IDE is and for most of the people here who are into programming this is not a new term. So here we are talking about different IDEs that are available for us as a data-engineer/enthusiast and to decide which one will be an ideal choice according to our needs.
Image Source
So, here we are going to mention five IDEs that are being helpful for the data scientists and engineers and are productive too. Based on their respective features you will be very easily to choose an IDE of your choice. Come let’s explore.
5 Best Python Machine Learning IDEs
1. Spyder
Coming to our very first focus i.e. Spyder. This IDE got this short name from it’s name itself: “Scientific Python Development Environment”. Pierre Raybaut is the author of Spyder and it got officially released on October 18, 2009 and is written solely in Python.
Features at a glance:
Very simple and light-weight IDE with detailed documentation and quite easy to install.
This is an open source editor and supports code completion, introspection, goto definition as well as horizontal and vertical splitting.
This editor comes with a Documentation Viewer where you can see the documentation related to classes or functions you gotta use.
Like most of the IDEs, this also supports Variable Explorer which is a helpful tool to explore and edit the variables that we have created during file execution.
It supports runtime debugging i.e. the errors will be seen on the screen as soon as you type them.
This IDE integrates with some of the crucial libraries like NumPy, Matplotlib, SciPy etc.
Spyder is considered best in the cases where it is been used as an interactive console for testing and development of scientific applications and scripts which make use of libraries such as SciPy, NumPy and Matplotlib.
Tip: Want to download? No need to bother we’ve got you covered. Click here to download your version of Spyder.
2. Geany
Geany is primarily a Python machine learning IDE authored by Enrico Troger and got officially released on October 19, 2005. It has been written in C & C++ and is a light-weight IDE. Despite of being a small IDE it is as capable as any other IDE present out there.
Features at a glance
Geany’s editor supports highlighting of the Syntax and line numebering.
It comes equipped with the features like code completion, auto closing of braces, auto HTML and XML tags closing.
It also comes with code folding.
This IDE supports code navigation.
Tip: Download your instance of Geany here.
3. Rodeo
This is special we got here. This is a Python IDE that primarily focuses and built for the purpose of machine learning and data science. This particular IDE use IPython kernel (you will know this later) and was authored by Yhat.
Features at a glance
It is mainly famous due to its ability to let users explore, compare and interact with the data frames & plots.
Like Geany’s editor this also comes with a editor that has capability of auto-completion, syntax highlighting.
This also provides a support for IPython making the code writing fast.
Also Rodeo comes with Python tutorials integrated within which makes it quite favourable for the users.
This IDE is well known for the fact that for the data scientists and engineers who work on RStudio IDE can very easily adapt to it.
Perfection doesn’t exist and so is the case for Rodeo, it doesn’t consist of code analysis, PEP 8, etc.
Tip: Download your Rodeo workspace here.
4. PyCharm
PyCharm is the IDE which is most famous in the professional world whether it is for data science or for conventional Python programming. This IDE is built by one of the big company out there that we all might have heard about: Jetbrains, company released the official version of PyCharm in October 2010.
PyCharm comes in two different editions: Community Edition which we all can have access to essentially for free and second one is the Professional Edition for which you will need to pay some bucks.
Features at a glance
It includes code completion, auto-indentation and code formatting.
This also comes with runtime debugger i.e. will display the errors as soon as you type them.
It contains PEP-8 that enables writing neat codes.
It consist of debugger for Javascript and Python with a GUI.
It has one of the most advanced documentation viewer along with video tutorials.
PyCharm being accepted widely among big companies for the purpose of Machine Learning is due to its ability to provide support for important libraries like Matplotlib, NumPy and Pandas.
Also PyCharm is capable of distinguishing between different environments (Python 2.7, Python 3.5) according to different project’s needs.
Tip: Download your version of Pycharm here.
5. JuPyter Notebook or IPython Notebook
Due to its simplicity this one became a sensational IDE among the data enthusiasts as it is the descendant of IPython. Best thing about JuPyter is that there you can very easily switch between the different versions of python (or any other language) according to your preference.
Features at a glance
It’s an open source platform
It can support up to 40 different languages to work on including languages beneficial for data sciences like R, Python, Julia, etc.
It supports sharing live codes, and even documents with equations and visualizations.
In JuPyter you can produce outputs in the form of images, videos and even LaTex with the help of several useful widgets.
You can even avail the advantage of Big Data tools due to the fact that JuPyter has got Big Data integration within to help the data scientists.
Tip: Download the JuPyter IDE here.
Conclusion
Since we have gone through all the IDEs that are famous in the field of Data Sciences and Machine Learning, now you must be able to make your choices based on the points we’ve discussed above.
Pro Tip: We would recommend our readers to use JuPyter Notebook if you are giving a start to ML. It has got that simplicity and features that most of the IDEs have combined. Apart from the features discussed above it also supports for data cleaning, transformation, etc. to help its users. Talking in terms of ML JuPyter has a good support for the libraries like Pandas, NumPy and Matplotlib. You can get complete guide on how to install and configure JuPyter here.
Comment down below if you know about any other good machine learning ide for python.
The post 5 Best Python Machine Learning IDEs appeared first on The Crazy Programmer.
0 notes
Text
Machine Learning for Data Analysis - Week 4 - Assignment
This blog is created to fulfill the course requirements for Machine Learning for Data Analysis.
This post outlines the week 4 course requirements for the peer graded assignment. The contents of this post include:
Summary of Dataset and Variables
K-Means Clustering Analysis
Analysis of Variance (ANOVA)
TUKEY Post Hoc Test
Python Code
My dataset contains the historical price of 9 financial stock funds over a period ranging from 1982 to 2017. The data is quantitative in nature and does not include categorical variables. Price indices for each stock fund are reported at the end (or close) of each trading day (excluding weekends). Out of the stock funds listed below, some are newer than other so not all funds go back to 1982. The stock fund data is obtained from www.yahoo.com/finance for each of the funds presented below:
S&P 500 (SP) – Response
Banking (FSRBX) – Explanatory
Technology (FSPTX) - Explanatory
Construction (FSHOX) – Explanatory
Energy (FSENX) - Explanatory
Defense (FSDAX) – Explanatory
Discretionary (FSCPX) – Explanatory
Industrial (FCYIX) – Explanatory
Commodities (FFGCX) - Explanatory
Figure 1 below depicts a uni-variate graph of each stock fund over time. The goal of this work is to evaluate the influence or response of a single stock fund (the S&P 500 or simply SP) to the other stock funds in the group. Evaluating the uni-variate plot in figure 1 below, the hypothesis for this study predicts that the S&P 500 is related to the performance of the other stock funds in this study, specifically the performance of banking (FSRBX), construction (FSHOX), discretionary (FSCPX), and defense (FSDAX) funds.

Figure 1: Uni-Variate Plot of 9 Stock Fund Price Indices
Before importing the data, the quantitative explanatory and response variables are converted to difference values instead of absolute price values. The reason for this is because the absolute price values steadily increase over time; therefore, the absolute magnitude of price doesn’t completely signify performance. The difference values are computed as price changes from the previous day. For example, if the price of a stock fund decreased from the previous day then the new quantitative variable is a negative value of the difference; whereas, an increase from the previous day is a positive value of the difference.
After import and cleaning, there are 1988 samples in the dataset dating back to March 25th 2009.
The quantitative explanatory variables are standardized to achieve a zero mean and a standard deviation of 1.
After standardization, the dataset is then subdivided into test and training datasets using a 70/30 split (i.e. 70% of the data used for training and 30% used for testing).
A k-means clustering analysis is performed to determine the clustering of the explanatory variables. A total of 9 clusters are evaluated to determine the optimal number of clusters required to cluster the data. The goal of the k-means clustering analysis is to identify underlying subgroups of explanatory variables in the dataset.
Figure 2 below shows the change in average distance of each parameter in the dataset with the cluster centroid as the number of clusters increases. As we expect, the average distance between variables decreases as the number of clusters increases; however, we see elbows in the chart where curve starts to flatten out. This flattening of the curve indicates the points of diminishing returns for additional clusters. This plot indicates that there are two classifications where the number of subgroups has a significant influence on average distance. For example, going from 1 to 2 clusters has a significant influence on average distance and going from 3 to 4 clusters has a significant influence on average distance. We can also see a slight change from 6 to 7 but the change is not very significant so we will ignore this point.

Figure 2: Average Distance vs. Number of Clusters
Figure 3 illustrates the regression coefficients determined for the LASSO regression model. As shown, only a single explanatory variable (FFGCX) is equal to zero. This means that this explanatory variable is insignificant in predicting the response variable. The most significant explanatory variables is FCYIX with the largest regression coefficient of 0.151. The least significant explanatory variable is FSDAX with the lowest regression coefficient of 0.028. The remaining 7 explanatory variables account for 70% of the variance in the S&P 500.

Figure 3: Scatter Plots of Canonical Variables (k=2,3)
Next, we evaluate the cluster means for the explanatory variables for k=2 and k=3 clusters. Figures 4 and 5 below illustrate the means for each of the explanatory variables in the k-means clusters. The cluster variable represents the number of cluster in the analysis. The tabulated data identifies the variable mean for each variable in the cluster. We will skip figure 4 and move to figure 5.

Figure 4: Cluster Variable Means (k=2)
Figure 5 shows the means for the 3-cluster analysis for all the explanatory variables. For cluster 0, the mean stock fund variables are all relatively high (around 1.1) except for a single stock fund (FFGCX) which is relatively low.

Figure 5: Cluster Variables Means (k=3)
An Analysis of Variance (ANOVA) is performed to determine if there is significant variance in the k-means clusters in the response variables. Figure 6 below illustrates the results of the OLS regression. We can see that the p-value is less than 0.05 which indicates that there is significant variance between the k-means clusters for the response variable.

Figure 6: Analysis of Variance for Response Variable Clusters (k=3)
Figure 7 illustrates the cluster means for the response variable clusters. This allows us to associate the clusters with the response variable. The means of the response variable cluster shows what the response variable looks like for each cluster.

Figure 7: Cluster Mean and Standard Deviation for Response Variable
Lastly, figure 7 illustrates the results the TUKEY test which is a post hoc test to evaluate difference between clusters on the response variable. The results of the TUKEY test confirm the results in the ANOVA in that there is significant difference in the response variable clusters. This is indicated by a TRUE response in the “reject” column.

Figure 8: TUKEY of Response Variable Clusters
PYTHON Code:
# -*- coding: utf-8 -*-
from pandas import DataFrame
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from sklearn.cross_validation import train_test_split
from sklearn import preprocessing
from sklearn.cluster import KMeans
import statsmodels.formula.api as smf
import statsmodels.stats.multicomp as multi
##############################################################
#import data
data = pd.read_csv("Data_Quantitative_Modified_2.csv", low_memory = True)
#data = pd.read_csv("Data_Categorical_Modified.csv", low_memory = True)
##############################################################
#changes all varaiable names in the data frame to uppercase
print("Converting data columns to uppercase...")
data.columns = map(str.upper, data.columns)
##############################################################
print("Cleaning data...")
data_clean = data.dropna()
#print(data_clean)
##############################################################
print("Finding data types...")
data_types = data_clean.dtypes
print(data_types)
##############################################################
print("Describing data...")
describe_data = data_clean.describe()
print(describe_data)
##############################################################
#set explanatory variables
print("Setting explanatory variables...")
explanatory = data[['FSRBX','FSPTX','FSHOX','FSENX','FSDAX','FSCPX','FCYIX','FFGCX']]
#explanatory = data[['FSRBX','FSHOX','FSDAX','FSCPX']]
print(data)
##############################################################
#standardize predictors to have mean=0 and sd=1
predictors=explanatory.copy() #delete this line
predictors['FSRBX']=preprocessing.scale(predictors['FSRBX'].astype('float64'))
predictors['FSPTX']=preprocessing.scale(predictors['FSPTX'].astype('float64'))
predictors['FSHOX']=preprocessing.scale(predictors['FSHOX'].astype('float64'))
predictors['FSENX']=preprocessing.scale(predictors['FSENX'].astype('float64'))
predictors['FSDAX']=preprocessing.scale(predictors['FSDAX'].astype('float64'))
predictors['FSCPX']=preprocessing.scale(predictors['FSCPX'].astype('float64'))
predictors['FCYIX']=preprocessing.scale(predictors['FCYIX'].astype('float64'))
predictors['FFGCX']=preprocessing.scale(predictors['FFGCX'].astype('float64'))
##############################################################
# split data into train and test sets
#clus_train, clus_test = train_test_split(clustervar, test_size=.3, random_state=123)
print("Splitting data into training and test sets...")
explanatory_train, explanatory_test = train_test_split(predictors, test_size=.3, random_state=123)
##############################################################
# k-means cluster analysis for 1-9 clusters
from scipy.spatial.distance import cdist
clusters=range(1,10)
meandist=[]
for k in clusters:
model=KMeans(n_clusters=k)
model.fit(explanatory_train)
clusassign=model.predict(explanatory_train)
meandist.append(sum(np.min(cdist(explanatory_train, model.cluster_centers_, 'euclidean'), axis=1))
/ explanatory_train.shape[0])
#############################################################
#print("Plot average distance distance..." )
#plt.plot(clusters, meandist)
#plt.xlabel('Number of clusters')
#plt.ylabel('Average distance')
#plt.title('Selecting k with the Elbow Method')
#
#pause
##############################################################
#evaluate cluster solutions
print("Evaluating cluster selections...")
model3=KMeans(n_clusters=3)
model3.fit(explanatory_train)
clusassign=model3.predict(explanatory_train)
##plot clusters
#print("Plotting clusters...")
#from sklearn.decomposition import PCA
#pca_2 = PCA(2) #returns first 2 canonical variables
#plot_columns = pca_2.fit_transform(explanatory_train)
#plt.scatter(x=plot_columns[:,0], y=plot_columns[:,1],c=model3.labels_,)
#plt.xlabel('Canonical Variable 1')
#plt.ylabel('Canonical Variable 2')
#plt.title('Scatterplot of Canonical Variables for 6 Clusters')
##plt.xlim(-10,10)
##plt.ylim(-10,10)
#plt.show()
#
#pause
#############################################################
# create a unique identifier variable from the index for the
# cluster training data to merge with the cluster assignment variable
explanatory_train.reset_index(level=0, inplace=True)
# create a list that has the new index variable
cluslist=list(explanatory_train['index'])
# create a list of cluster assignments
labels=list(model3.labels_)
# combine index variable list with cluster assignment list into a dictionary
newlist=dict(zip(cluslist, labels))
newlist
# convert newlist dictionary to a dataframe
newclus=DataFrame.from_dict(newlist, orient='index')
newclus
# rename the cluster assignment column
newclus.columns = ['cluster']
# now do the same for the cluster assignment variable
# create a unique identifier variable from the index for the
# cluster assignment dataframe
# to merge with cluster training data
newclus.reset_index(level=0, inplace=True)
# merge the cluster assignment dataframe with the cluster training variable dataframe
# by the index variable
merged_train=pd.merge(explanatory_train, newclus, on='index')
merged_train.head(n=100)
# cluster frequencies
merged_train.cluster.value_counts()
"""
END multiple steps to merge cluster assignment with clustering variables to
examine cluster variable means by cluster
"""
#############################################################
# FINALLY calculate clustering variable means by cluster
clustergrp = merged_train.groupby('cluster').mean()
print ("Clustering variable means by cluster...")
print(clustergrp)
#pause
##############################################################
#get the response variable
sp_data=data_clean['SP']
#split response data into train and test sets
sp_train,sp_test = train_test_split(sp_data, test_size=.3, random_state=123)
#add training data to a dataframe
sp_train1=pd.DataFrame(sp_train)
#reset level in training dataframe
sp_train1.reset_index(level=0, inplace=True)
#merge response variable with cluster variables
merged_train_all=pd.merge(sp_train1, merged_train, on='index')
#drop NANs merged dataframe
sub1 = merged_train_all[['SP', 'cluster']].dropna()
#Use the OLS function to test ANOVA for the categorical variable ('cluster')
print("Performing Analysis of variance between sliset")
spmod = smf.ols(formula='SP ~ C(cluster)', data=sub1).fit()
print (spmod.summary())
##############################################################
#compute mean and standard deviation
print ('Means for SP by cluster...')
m1= sub1.groupby('cluster').mean()
print (m1)
print ('Standard deviations for SP by cluster...')
m2= sub1.groupby('cluster').std()
print (m2)
##############################################################
mc1 = multi.MultiComparison(sub1['SP'], sub1['cluster'])
res1 = mc1.tukeyhsd()
print(res1.summary())
0 notes
Text
April 29, 2020 at 10:00PM - The Complete Python Data Science Bundle (96% discount) Ashraf
The Complete Python Data Science Bundle (96% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
It’s no secret that data scientists stand to make a pretty penny in today’s data-driven world; but if you’re keen on becoming one, you’ll need to master the appropriate tools. Pandas is one of the most popular of the Python data science libraries for working with mounds of data. By expressing data in a tabular format, Pandas makes it easy to perform data cleaning, aggregations and other analyses. Built around hands-on demos, this course will walk you through using Pandas and what it can do as you take on series, data frames, importing/exporting data, and more.
Access 23 lectures & 2.5 hours of content 24/7
Explore Panda’s built-in functions for common data manipulation techniques
Learn how to work with data frames & manage data
Deepen your understanding w/ example-driven lessons
Today’s companies collect and utilize a staggering amount of data to guide their business decisions. But, it needs to be properly cleaned and organized before it can be put to use. Enter NumPy, a core library in the Python data science stack used by data science gurus to wrangle vast amounts of multidimensional data. This course will take you through NumPy’s basic operations, universal functions, and more as you learn from hands-on examples.
Access 27 lectures & 2.5 hours of content 24/7
Familiarize yourself w/ NumPy’s basic operations & universal functions
Learn how to properly manage data w/ hands-on examples
Validate your training w/ a certificate of completion
From tech to medicine and finance, data plays a pivotal role in guiding today’s businesses. But, it needs to be properly broken down and visualized before you can get any sort of actionable insights. That’s where Seaborn comes into play. Designed for enhanced data visualization, this Python-based library helps bridge the gap between vast swathes of data and the valuable insights they contain. This course acts as your Seaborne guide, walking you through what it can do and how you can use it to display information, find relationships, and much more.
Access 16 lectures & 1.5 hours of content 24/7
Familiarize yourself w/ Seaborn via hands-on examples
Discover Seaborn’s enhanced data visualization capabilities
Explore histograms, linear relationships & more visualization concepts
Before a data scientist can properly analyze their data, they must first visualize it and understand any relationships that might exist in the information. To this end, many data professionals use Matplotlib, an industry-favorite Python library for visualizing data. Highly customizable and packed with powerful features for building graphs and plots, Matplotlib is an essential tool for any aspiring data scientist, and this course will show you how it ticks.
Access 30 lectures & 3 hours of content 24/7
Explore the anatomy of a Matplotlib figure & its customizable parts
Dive into figures, axes, subplots & more components
Learn how to draw statistical insights from data
Understand different ways of conveying statistical information
One of the most popular data analytics engines out there, Spark has become a staple in many a data scientist’s toolbox; and the latest version, Spark 2.x, brings more efficient and intuitive features to the table. Jump into this comprehensive course, and you’ll learn how to better analyze mounds of data, extract valuable insights, and more with Spark 2.x. Plus, this course comes loaded with hands-on examples to refine your knowledge, as you analyze data from restaurants listed on Zomato and churn through historical data from the Olympics and the FIFA world cup!
Access 27 lectures & 3 hours of content 24/7
Explore what Spark 2.x can do via hands-on projects
Learn how to analyze data at scale & extract insights w/ Spark transformations and actions
Deepen your understanding of data frames & Resilient Distributed Datasets
You don’t need to be a programming prodigy to get started in data science. Easy to use and highly accessible, Plotly is library in Python that lets you create complex plots and graphs with minimal programming know-how. From creating basic charts to adding motion to your visualizations, this course will walk you through the Plotly essentials with hands-on examples that you can follow.
Access 27 lectures & 2 hours of content 24/7
Learn how to build line charts, bar charts, histograms, pie charts & other basic visualizations
Explore visualizing data in more than two dimensions
Discover how to add motion to your graphs
Work w/ plots on your local machine or share them via the Plotly Cloud
In addition to handling vast amounts of batch data, Spark has extremely powerful support for continuous applications, or those with streaming data that is constantly updated and changes in real-time. Using the new and improved Spark 2.x, this course offers a deep dive into stream architectures and analyzing continuous data. You’ll also follow along a number of real-world examples, like analyzing data from restaurants listed on Zomato and real-time Twitter data.
Access 36 lectures & 2.5 hours of content 24/7
Familiarize yourself w/ Spark 2.x & its support for continuous applications
Learn how to analyze data from real-world streams
Analyze data from restaurants listed on Zomato & real-time Twitter data
More companies are using the power of deep learning and neural networks to create advanced AI that learns on its own. From speech recognition software to recommendation systems, deep learning frameworks, like PyTorch, make creating these products easier. Jump in, and you’ll get up to speed with PyTorch and its capabilities as you analyze a host of real-world datasets and build your own machine learning models.
Access 41 lectures & 3.5 hours of content 24/7
Understand neurons & neural networks and how they factor into machine learning
Explore the basic steps involved in training a neural network
Familiarize yourself w/ PyTorch & Python 3
Analyze air quality data, salary data & more real-world datasets
Fast, scalable, and packed with an intuitive API for machine learning, Apache MXNet is a deep learning framework that makes it easy to build machine learning applications that learn quickly and can run on a variety of devices. This course walks you through the Apache MXNet essentials so you can start creating your own neural networks, the building blocks that allow AI to learn on their own.
Access 31 lectures & 2 hours of content 24/7
Explore neurons & neural networks and how they factor into machine learning
Walk through the basic steps of training a neural network
Dive into building neural networks for classifying images & voices
Refine your training w/ real-world examples & datasets
Python is a general-purpose programming language which can be used to solve a wide variety of problems, be they in data analysis, machine learning, or web development. This course lays a foundation to start using Python, which considered one of the best first programming languages to learn. Even if you’ve never even thought about coding, this course will serve as your diving board to jump right in.
Access 28 lectures & 3 hours of content 24/7
Gain a fundamental understanding of Python loops, data structures, functions, classes, & more
Learn how to solve basic programming tasks
Apply your skills confidently to solve real problems
Classification models play a key role in helping computers accurately predict outcomes, like when a banking program identifies loan applicants as low, medium, or high credit risks. This course offers an overview of machine learning with a focus on implementing classification models via Python’s scikit-learn. If you’re an aspiring developer or data scientist looking to take your machine learning knowledge further, this course is for you.
Access 17 lectures & 2 hours of content 24/7
Tackle basic machine learning concepts, including supervised & unsupervised learning, regression, and classification
Learn about support vector machines, decision trees & random forests using real data sets
Discover how to use decision trees to get better results
Deep learning isn’t just about helping computers learn from data—it’s about helping those machines determine what’s important in those datasets. This is what allows for Tesla’s Model S to drive on its own and for Siri to determine where the best brunch spots are. Using the machine learning workhorse that is TensorFlow, this course will show you how to build deep learning models and explore advanced AI capabilities with neural networks.
Access 62 lectures & 8.5 hours of content 24/7
Understand the anatomy of a TensorFlow program & basic constructs such as graphs, tensors, and constants
Create regression models w/ TensorFlow
Learn how to streamline building & evaluating models w/ TensorFlow’s estimator API
Use deep neural networks to build classification & regression models
from Active Sales – SharewareOnSale https://ift.tt/2OYNcYd https://ift.tt/eA8V8J via Blogger https://ift.tt/2Wgn5l4 #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
March 07, 2020 at 10:00PM - The Complete Big Data Master Class Bundle (96% discount) Ashraf
The Complete Big Data Master Class Bundle (96% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
You don’t need to be a programming prodigy to get started in data science. Easy to use and highly accessible, Plotly is library in Python that lets you create complex plots and graphs with minimal programming know-how. From creating basic charts to adding motion to your visualizations, this course will walk you through the Plotly essentials with hands-on examples that you can follow.
Access 28 lectures & 2 hours of content 24/7
Learn how to build line charts, bar charts, histograms, pie charts & other basic visualizations
Explore visualizing data in more than two dimensions
Discover how to add motion to your graphs
Work w/ plots on your local machine or share them via the Plotly Cloud
Before a data scientist can properly analyze their data, they must first visualize it and understand any relationships that might exist in the information. To this end, many data professionals use Matplotlib, an industry-favorite Python library for visualizing data. Highly customizable and packed with powerful features for building graphs and plots, Matplotlib is an essential tool for any aspiring data scientist, and this course will show you how it ticks.
Access 30 lectures & 3 hours of content 24/7
Explore the anatomy of a Matplotlib figure & its customizable parts
Dive into figures, axes, subplots & more components
Learn how to draw statistical insights from data
Understand different ways of conveying statistical information
Bokeh is an open-source, easy-to-use and highly accessible library in Python which allows even developers with just basic programming ability to get up and running with complex plots and graphs. Far easier to use than competing frameworks such as Matplotlib, Bokeh is especially compelling because of how easy it is to build interactivity into your visualizations. Explore relationships in your data without in-depth programming knowledge, extract insights which can be used for further analysis on your data.
Access 21 lectures & 1 hour of content 24/7
Structure your visuals in the right format
Customize the look & feel of basic line plots
Plot stacked graphs & bar charts w/ multi-level data
Visualize nodes & edges in network graphs
Use Bokeh’s built-in libraries to view maps & plot geo-location data
Add interactivity to legends, tooltips, & toolbars, and use plot tools to play w/ and modify data
Use the model-view-controller paradigm to separate data & visualization to build custom, interactive plots
From tech to medicine and finance, data plays a pivotal role in guiding today’s businesses. But, it needs to be properly broken down and visualized before you can get any sort of actionable insights. That’s where Seaborn comes into play. Designed for enhanced data visualization, this Python-based library helps bridge the gap between vast swathes of data and the valuable insights they contain. This course acts as your Seaborne guide, walking you through what it can do and how you can use it to display information, find relationships, and much more.
Access 16 lectures & 1 hour of content 24/7
Familiarize yourself w/ Seaborn via hands-on examples
Discover Seaborn’s enhanced data visualization capabilities
Explore histograms, linear relationships & more visualization concepts
Today’s companies collect and utilize a staggering amount of data to guide their business decisions. But, it needs to be properly cleaned and organized before it can be put to use. Enter NumPy, a core library in the Python data science stack used by data science gurus to wrangle vast amounts of multidimensional data. This course will take you through NumPy’s basic operations, universal functions, and more as you learn from hands-on examples.
Access 27 lectures & 2 hours of content 24/7
Familiarize yourself w/ NumPy’s basic operations & universal functions
Learn how to properly manage data w/ hands-on examples
Validate your training w/ a certificate of completion
It’s no secret that data scientists stand to make a pretty penny in today’s data-driven world; but if you’re keen on becoming one, you’ll need to master the appropriate tools. Pandas is one of the most popular of the Python data science libraries for working with mounds of data. By expressing data in a tabular format, Pandas makes it easy to perform data cleaning, aggregations and other analyses. Built around hands-on demos, this course will walk you through using Pandas and what it can do as you take on series, data frames, importing/exporting data, and more.
Access 23 lectures & 2.5 hours of content 24/7
Explore Panda’s built-in functions for common data manipulation techniques
Learn how to work with data frames & manage data
Deepen your understanding w/ example-driven lessons
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 72 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Hive helps you leverage the power of distributed computing and Hadoop for Analytical processing. Its interface is similar to SQL and this course will help you fill in all the gaps between SQL and what you need to use Hive. It’s an end-to-end guide for using Hive: whether you’re an analyst who wants to process data or an engineer who needs to build custom functionality or optimize performance, everything you need is right here.
Access 73 lectures & 13 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning, bucketing to optimize queries in Hive
Customize Hive w/ user-defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Python is a general-purpose programming language which can be used to solve a wide variety of problems, be they in data analysis, machine learning, or web development. This course lays a foundation to start using Python, which considered one of the best first programming languages to learn. Even if you’ve never even thought about coding, this course will serve as your diving board to jump right in.
Access 28 lectures & 3 hours of content 24/7
Gain a fundamental understanding of Python loops, data structures, functions, classes, & more
Learn how to solve basic programming tasks
Apply your skills confidently to solve real problems
from Active Sales – SharewareOnSale https://ift.tt/2IqOZob https://ift.tt/eA8V8J via Blogger https://ift.tt/2IvpDW4 #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes
Text
February 05, 2020 at 10:00PM - The Complete Big Data Master Class Bundle (96% discount) Ashraf
The Complete Big Data Master Class Bundle (96% discount) Hurry Offer Only Last For HoursSometime. Don't ever forget to share this post on Your Social media to be the first to tell your firends. This is not a fake stuff its real.
You don’t need to be a programming prodigy to get started in data science. Easy to use and highly accessible, Plotly is library in Python that lets you create complex plots and graphs with minimal programming know-how. From creating basic charts to adding motion to your visualizations, this course will walk you through the Plotly essentials with hands-on examples that you can follow.
Access 28 lectures & 2 hours of content 24/7
Learn how to build line charts, bar charts, histograms, pie charts & other basic visualizations
Explore visualizing data in more than two dimensions
Discover how to add motion to your graphs
Work w/ plots on your local machine or share them via the Plotly Cloud
Before a data scientist can properly analyze their data, they must first visualize it and understand any relationships that might exist in the information. To this end, many data professionals use Matplotlib, an industry-favorite Python library for visualizing data. Highly customizable and packed with powerful features for building graphs and plots, Matplotlib is an essential tool for any aspiring data scientist, and this course will show you how it ticks.
Access 30 lectures & 3 hours of content 24/7
Explore the anatomy of a Matplotlib figure & its customizable parts
Dive into figures, axes, subplots & more components
Learn how to draw statistical insights from data
Understand different ways of conveying statistical information
Bokeh is an open-source, easy-to-use and highly accessible library in Python which allows even developers with just basic programming ability to get up and running with complex plots and graphs. Far easier to use than competing frameworks such as Matplotlib, Bokeh is especially compelling because of how easy it is to build interactivity into your visualizations. Explore relationships in your data without in-depth programming knowledge, extract insights which can be used for further analysis on your data.
Access 21 lectures & 1 hour of content 24/7
Structure your visuals in the right format
Customize the look & feel of basic line plots
Plot stacked graphs & bar charts w/ multi-level data
Visualize nodes & edges in network graphs
Use Bokeh’s built-in libraries to view maps & plot geo-location data
Add interactivity to legends, tooltips, & toolbars, and use plot tools to play w/ and modify data
Use the model-view-controller paradigm to separate data & visualization to build custom, interactive plots
From tech to medicine and finance, data plays a pivotal role in guiding today’s businesses. But, it needs to be properly broken down and visualized before you can get any sort of actionable insights. That’s where Seaborn comes into play. Designed for enhanced data visualization, this Python-based library helps bridge the gap between vast swathes of data and the valuable insights they contain. This course acts as your Seaborne guide, walking you through what it can do and how you can use it to display information, find relationships, and much more.
Access 16 lectures & 1 hour of content 24/7
Familiarize yourself w/ Seaborn via hands-on examples
Discover Seaborn’s enhanced data visualization capabilities
Explore histograms, linear relationships & more visualization concepts
Today’s companies collect and utilize a staggering amount of data to guide their business decisions. But, it needs to be properly cleaned and organized before it can be put to use. Enter NumPy, a core library in the Python data science stack used by data science gurus to wrangle vast amounts of multidimensional data. This course will take you through NumPy’s basic operations, universal functions, and more as you learn from hands-on examples.
Access 27 lectures & 2 hours of content 24/7
Familiarize yourself w/ NumPy’s basic operations & universal functions
Learn how to properly manage data w/ hands-on examples
Validate your training w/ a certificate of completion
It’s no secret that data scientists stand to make a pretty penny in today’s data-driven world; but if you’re keen on becoming one, you’ll need to master the appropriate tools. Pandas is one of the most popular of the Python data science libraries for working with mounds of data. By expressing data in a tabular format, Pandas makes it easy to perform data cleaning, aggregations and other analyses. Built around hands-on demos, this course will walk you through using Pandas and what it can do as you take on series, data frames, importing/exporting data, and more.
Access 23 lectures & 2.5 hours of content 24/7
Explore Panda’s built-in functions for common data manipulation techniques
Learn how to work with data frames & manage data
Deepen your understanding w/ example-driven lessons
Big Data sounds pretty daunting doesn’t it? Well, this course aims to make it a lot simpler for you. Using Hadoop and MapReduce, you’ll learn how to process and manage enormous amounts of data efficiently. Any company that collects mass amounts of data, from startups to Fortune 500, need people fluent in Hadoop and MapReduce, making this course a must for anybody interested in data science.
Access 72 lectures & 13 hours of content 24/7
Set up your own Hadoop cluster using virtual machines (VMs) & the Cloud
Understand HDFS, MapReduce & YARN & their interaction
Use MapReduce to recommend friends in a social network, build search engines & generate bigrams
Chain multiple MapReduce jobs together
Write your own customized partitioner
Learn to globally sort a large amount of data by sampling input files
Hive helps you leverage the power of distributed computing and Hadoop for Analytical processing. Its interface is similar to SQL and this course will help you fill in all the gaps between SQL and what you need to use Hive. It’s an end-to-end guide for using Hive: whether you’re an analyst who wants to process data or an engineer who needs to build custom functionality or optimize performance, everything you need is right here.
Access 73 lectures & 13 hours of content 24/7
Write complex analytical queries on data in Hive & uncover insights
Leverage ideas of partitioning, bucketing to optimize queries in Hive
Customize Hive w/ user-defined functions in Java & Python
Understand what goes on under the hood of Hive w/ HDFS & MapReduce
Python is a general-purpose programming language which can be used to solve a wide variety of problems, be they in data analysis, machine learning, or web development. This course lays a foundation to start using Python, which considered one of the best first programming languages to learn. Even if you’ve never even thought about coding, this course will serve as your diving board to jump right in.
Access 28 lectures & 3 hours of content 24/7
Gain a fundamental understanding of Python loops, data structures, functions, classes, & more
Learn how to solve basic programming tasks
Apply your skills confidently to solve real problems
from Active Sales – SharewareOnSale https://ift.tt/2CreCT4 https://ift.tt/eA8V8J via Blogger https://ift.tt/374tl2R #blogger #bloggingtips #bloggerlife #bloggersgetsocial #ontheblog #writersofinstagram #writingprompt #instapoetry #writerscommunity #writersofig #writersblock #writerlife #writtenword #instawriters #spilledink #wordgasm #creativewriting #poetsofinstagram #blackoutpoetry #poetsofig
0 notes